This content originally appeared on Level Up Coding – Medium and was authored by Wadix Technologies

{kind=link}
1.Introduction
For decades, CPU designers focused on one main objective: execution speed. To boost performance, they increased clock frequencies and added deeper pipelines — breaking instructions into smaller steps so more operations could run in parallel.
But this strategy hit its limits. Faster clocks created problems with heat and power. Longer pipelines added complexity, with diminishing returns. And through all this, CPUs kept hitting the same wall: memory access latency.
Memory — especially main RAM — is painfully slow compared to the speed of a modern processor. The CPU often ends up waiting, doing nothing, just to get the data it needs. No matter how fast the CPU gets, it’s still bottlenecked by how fast it can talk to memory.
To get around this, CPU designers started thinking differently.
What if, instead of waiting, the CPU just moved on? If two instructions don’t depend on each other, why not run them out of order? If the result is still correct, we save time.
This idea led to out-of-order execution — a key optimization that keeps CPUs busy instead of stalled. But as powerful as it is, it comes with a hidden cost.
In concurrent systems, reordering can break memory consistency. One thread may see operations in a different order than another. Writes might not become visible when we expect them to. And on some architectures — like ARM — these effects are not rare corner cases. They’re part of the design.
In this article, we’ll explore what memory consistency really means, how instruction reordering affects it, and why understanding it is critical when writing multithreaded programs on modern hardware.
2. The Sequential Memory Model
“The result of any execution is the same as if the operations of all the processors were executed in some sequential order…”
— Leslie Lamport
For a long time, processors worked pretty much the way you’d expect: one instruction runs after another, exactly in the order you wrote them.
If a program writes to memory, and then reads from it, that’s the order it happens. All threads see things the same way. Simple, predictable.
This is called the sequential memory model. It matched how people thought about code, and it worked fine — back when CPUs were simpler.
But that kind of order comes with a cost. And eventually, that cost got too high.

3. Why Sequential Memory Hurts Performance
The sequential memory model is simple — but it’s not built for speed.
Modern CPUs use pipelines to run parts of several instructions at the same time, like an assembly line. This helps increase performance, but only if each step keeps moving. If one instruction has to wait (like for a memory read), the whole pipeline can stall — and everything behind it gets delayed too.
That’s exactly what happens with strict sequential execution. Even if later instructions have nothing to do with the stalled one, they still have to wait — just because of the order.
And memory is slow. Much slower than the CPU. So when a memory access blocks the pipeline, it wastes a lot of potential performance. The CPU ends up waiting more than it works.
This is where the sequential model becomes a real problem. It forces the CPU to stay idle when it could be doing other useful work.

4. The Idea of Reordering
So what happens when the CPU hits a delay, like waiting for data from memory?
It moves on.
Modern CPUs, like ARM Cortex-A processors, are designed to make the most of every cycle. If one instruction is blocked, the CPU doesn’t just wait — it looks ahead and runs something else that’s ready, as long as it doesn’t depend on the stalled instruction.
For example, imagine this code:
a = load_from_memory();
b = 10;
c = b * 2
Since b and c don’t rely on a, the CPU can go ahead and execute those lines while it waits for the memory load. The result is the same in the end — but the work gets done faster.
5. From Reordering to Broken Consistency
Memory consistency is about the order in which memory changes happen and how that order is seen by other observers. Even if a thread runs its instructions one after the other, modern CPUs don’t always stick to that exact order behind the scenes. To speed things up, they may reorder operations — running some instructions earlier if they’re ready, even if that’s not how they appear in the code. This is usually fine in single-threaded programs, but in concurrent systems, it becomes a challenge.
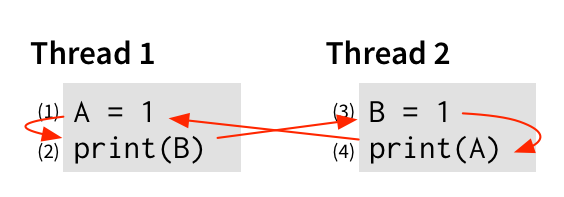
Each thread often runs on a separate core, with its own caches. So, even if one thread writes to memory, that change may not be immediately visible to another thread running elsewhere. If both threads reorder instructions and see stale or partial updates, things can go very wrong. What looked like a simple, predictable program can suddenly behave in strange and unexpected ways. This is what we mean by broken consistency: different parts of the system no longer agree on what happened — or in what order.
Let’s take an example of a mailbox: one thread sets a flag before writing data, and another thread reads that flag and then reads the data but due to reordering, the second thread may read the wrong value.

6. Avoiding Consistency Problems
Unlike cache coherence, which is handled automatically by hardware to keep data synchronized between caches, memory consistency has no such built-in guarantee.
The CPU might execute instructions out of order or delay making memory changes visible to other cores. This means the responsibility falls on the developer to ensure correctness in concurrent code.
One way to handle this is by using memory barriers — special instructions that prevent certain kinds of reordering. On ARM systems, for example, the DMB (Data Memory Barrier) instruction is used to make sure that all memory accesses before the barrier are globally visible before any accesses that come after.
Let’s revisit the mailbox example from earlier, this time in simplified assembly to show where the barriers need to be placed:
Sender (Thread 1)
STR R1, [MAILBOX]
DMB ISH / *ensure message is globally visible * /
STR R2, [FLAG]
Receiver (Thread 2)
LDR R3, [FLAG]
CMP R3, #1
BEQ ready
DMB ISH /* ensure flag is really set before reading/
LDR R4, [MAILBOX]
In C, this kind of ordering can be enforced using a generic memory barrier function like __sync_synchronize().
7.Conclusion:
Modern CPUs reorder instructions to gain performance, but this can lead to unexpected behaviors in concurrent programs. Memory consistency is not guaranteed by hardware and must be managed explicitly by developers. Understanding and using memory barriers correctly is essential for writing safe, reliable multithreaded code.
If you enjoyed this article, please make sure to Subscribe, Clap, Comment and Check out our online courses today!
Instruction Reordering and the Challenge of Memory Consistency was originally published in Level Up Coding on Medium, where people are continuing the conversation by highlighting and responding to this story.
This content originally appeared on Level Up Coding – Medium and was authored by Wadix Technologies