This content originally appeared on Level Up Coding – Medium and was authored by Nikita Prasad
An illustrated guide to most powerful capability of the Transformers!

Previously, I covered a high-level overview about the backbone of Large Language Models (LLMs) — the Transformer architecture, as proposed in the ‘Attention Is All You Need’ paper [1].
And so, we know that Self-Attention is a mechanism that allows the transformer model to weigh the contextual importance of different tokens within the input sequence of a sentence.
If you missed it (really?), go check it out. And while you’re at it, follow me so as you’ll not miss any more of these contents.
Today, we’ll dive deep into the Self-Attention Mechanism. By the end of this, you’ll be able to answer the following burning questions:
- Why do we need the Self-Attention Mechanism?
- What’s inside the attention block?
- How does the Self-Attention Models work?
So, buckle up, and let’s get started!
Answering the first and foremost question!
Why Do We Need the Self-Attention Mechanism?
Alright, we have already discussed that the traditional deep learning models struggled to capture long-range dependencies and contextual information effectively from the sequential data.
But other than this, have you wondered, “What is the most important requirement to build any Natural Language Processing (NLP) Application?”
I hope you guessed it right! It’s the conversion of words to numbers, called Vectorization.
Earlier the input sequence was typically represented as a set of vectors where each vector represents a token in the corpus, produced through methods like One-Hot Encoding, Bag of Words, TF-IDF, which heavily rely on word frequencies.
But these methods struggle to capture the significant meaning conveyed by the phrases such as “money bank” and “river bank” used in the same sentence, something like “She visited the money bank, near the river bank.”
To overcome this problem, we used “Word Embeddings”, which were powerful enough to capture the semantic meaning of words to find the similarity between the tokens, represented by a dimensional vector, dₘ (which can be of 512, 256, or even 64 dimensions).
Cool right!
But the problem with them was that they were the Static Embeddings. Meaning, these vectors are created through training on a large corpus of text and then use them in various NLP tasks. Such that they capture only the average meaning for the token, regardless of the context in which the word has appeared.
For example, the word “bank” will have the same vector whether it’s used in the context of a financial institution or the side of a river.
 That’s why we use “Self-Attention” Mechanism to generate sensible “Contextual Embeddings” using “Static Embeddings” as input.
That’s why we use “Self-Attention” Mechanism to generate sensible “Contextual Embeddings” using “Static Embeddings” as input.

It allows dynamic understanding of context in any NLP tasks, depending on the surrounding words.
Now let’s explore!
What’s Inside the Self-Attention Block?
The attention mechanism operates on three inputs:
- Queries (Q): This matrix is the word we’re currently focusing on.
- Keys (K): This matrix represent all the words in the document we’re comparing our query to.
- Values (V): This matrix hold the actual context for each word in the input document.
These are the important components behind the self-attention mechanism. As they allow the model to look at a word (query), then compare it to every other word (keys), and lastly, decide how much attention to give to each word (values).
So, you’ve got the gist that self-attention deals with only one type of input sequence. But what exactly does that mean?
Time to dive into the mechanics.
How Does Self-Attention Work?
Let’s unpack it step by step.

Step 1: Compute the Query, Key, and Value Matrices
First, we transform each token of our sentence into three different vectors Q, K, and V.
Query, Key and Value matrices are calculated through the matrix multiplication of an input matrix X and a weight matrix W (it’s a learnable parameter).
Step 2: Calculate Attention Scores
Next, we calculate how much each word should pay attention to every other word. This is done by taking the dot product of the Query and Key matrices.
This outputted matrix denotes the similarity (or simply the compatibility) between two input vectors.
Step 3: Scaling the Scores
(Important) While dealing with high-dimensionality matrices, the dot product leads to very large variance. This can cause instability in the model.
Here’s why:
During backpropagation, the softmax function would produce extremely large gradients, for large dot product values. This results in negligible updates of smaller dot product values during the training process, due to small gradients, leading the model towards the vanishing gradient problem.
Therefore, to mitigate this problem, the dot products are scaled by a square root of the dimensionality of Key vectors i.e., √dₖ.
This is why, it is known as Scaled-Dot Product Attention.
Step 4: Apply the Softmax Function
We then pass these scaled scores through a softmax function to normalise the values between 0 to 1.
This is to ensure that the compatibility scores follow a probability distribution, with the weights of each token summing to 1 or 100%, known as the Attention Weight Matrix.

And from my past article, we know that, these probability values represent how much attention each token in the sequence should get, indicating their importance and contribution to the final context vector.
Step 5: Weight the Values
These probabilities are used to calculate the weighted multiplication with the Value matrix.
Finally, this will gives us the text specific contextual output embeddings.
Alright, so we’ve talked about self-attention and how it allows the model to focus on different parts of the input sequence. But what if we could do this multiple times, from different perspectives?
Consider this sentence, “The bank can be a lifesaver.”
Does this refer to a financial institution, or the side of a river?
That’s where multi-head attention comes in.
Multi-Head Attention
It is an extension of Self-Attention Mechanism used in Transformer Architecture [1], allowing it to focus on different parts of an input sequence simultaneously, capturing multiple perspectives.
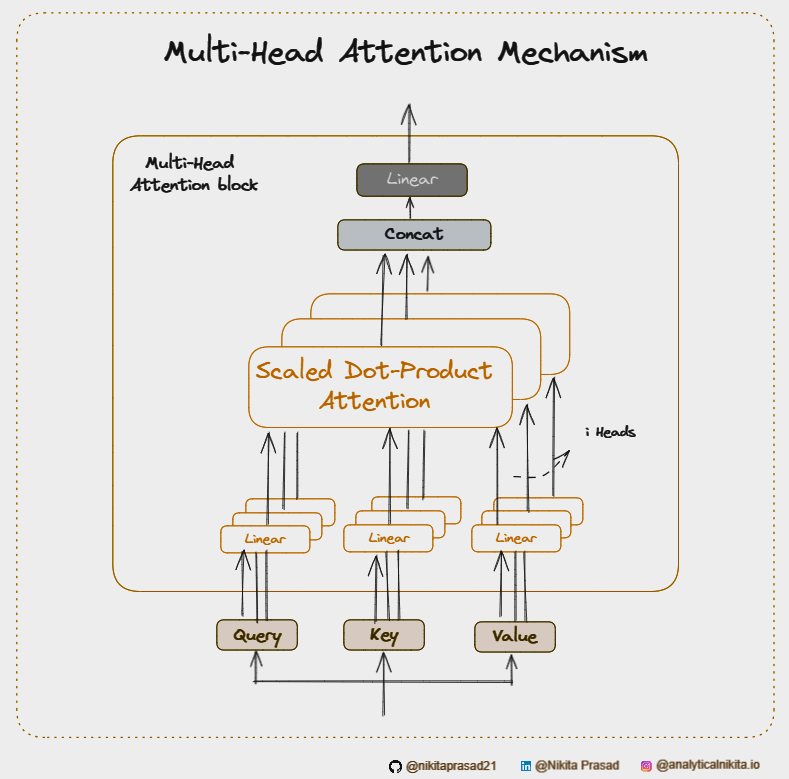
In multi-head attention, above process is repeated multiple times with different linear projections of the queries, keys, and values matrices.
Here’s it gets a bit math-y, but stay with me:
Step 1: Linear Projections
For each head, the input sequence is linearly projected into queries, keys, and values using learned weight matrices:

Step 2: Scaled Dot-Product Attention
Each set of queries, keys, and values matrices undergoes the scaled dot-product attention mechanism, independently:
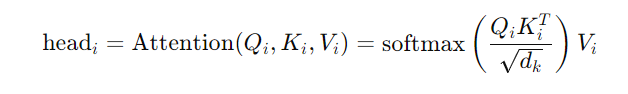
Step 3: Concatenation
Now, the outputs of all attention heads are concatenated:

Step 4: Final Linear Projection
Lastly, the concatenated output is then projected using another learned weight matrix to produce the final output:

Hence, using multiple heads means that each head can focus on different parts of the input sequence simultaneously. One head might pick up on the overall structure of the sentence, while another focuses on specific details, parallelly.
When you combine all these perspectives, you’ll get a more comprehensive understanding of the input sequence (same as we human do).
Cross-Attention: Bridging the Encoder and Decoder
Now, let’s talk about cross-attention. While self-attention deals with a single input sequence, cross-attention involves two different input sequences.
Simply putting, that’s the only difference.
This is crucial in tasks like machine translation, where you’re dealing with a source language (like English) and a target language (like French) [1].
Cross-attention acts as the bridge between the encoder and decoder in a transformer model [1]. Here’s how it works:
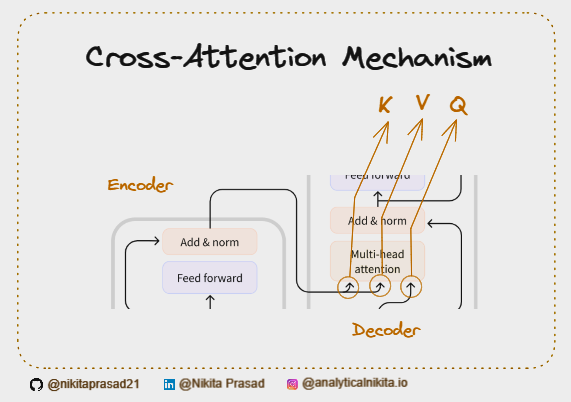
- Encoder Output: The encoder processes the source language (English) and produces a set of encoded representations.
- Decoder Input: The decoder takes the target language (French) input sequence.
- Cross-Attention: The output of the encoder (encoded representations) is used as the Key and Value in the cross-attention mechanism, while the Query comes from the decoder’s input sequence, to Masked Multi-Head Attention.
So, why is this important?
By using cross-attention mechanism, the model will be able to learn different language conversion patterns between the two sequences, leading to more accurate and fluent translations.
So, we’ve talked about multi-head attention. But what about masked multi-head attention?
This is where things get even more interesting, especially when it comes to tasks like language modeling and text generation.
Masked Multi-Head Attention
It is a type of multi-head attention used primarily in the decoder part of the Transformer architecture [1]. It’s designed to ensure that during training, the model should not “cheat” by looking at future tokens while predicting the next-token in a sequence.
How Does Masked Multi-Head Attention Work?
Alright, let’s break down, the process of ‘Masking the Future Tokens’:
In masked multi-head attention, we simply introduce a mask that prevents each token from attending to any future tokens.
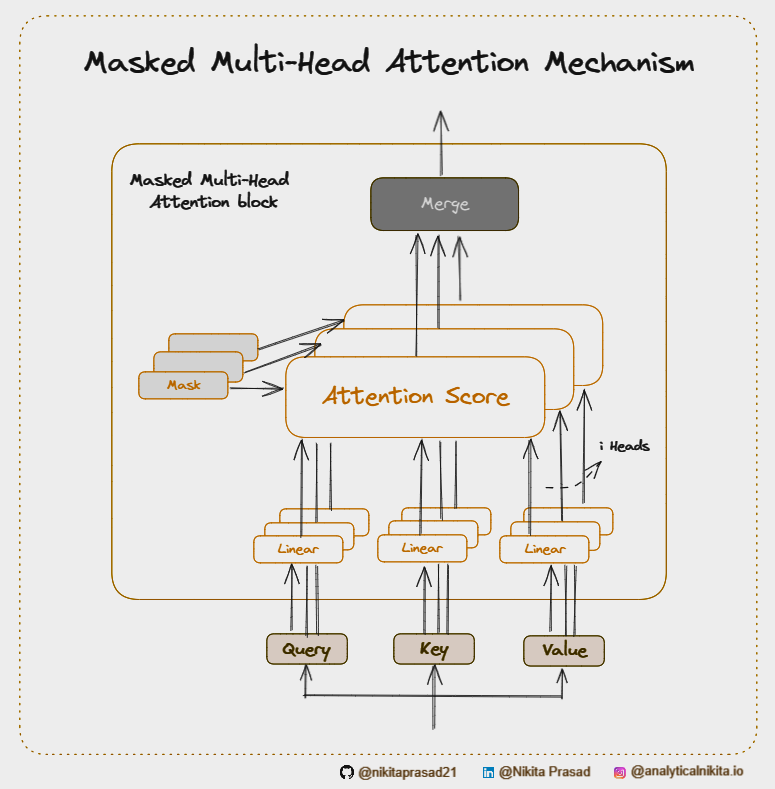
This is usually implemented by setting the attention scores of these future tokens to a very large negative number (or negative infinity) before applying the softmax function to effectively nullify their influence.
The Masked-Attention mechanism can be represented as:

Just like regular multi-head attention, masked attention can also be applied across multiple heads.
Each head operates independently, learns different aspects of the input, and then the results are concatenated and linearly projected to form the final output.
Why It Matters?
Because it allows the model to generate coherent and contextually accurate sequences (one token at a time), without peeking onto future information, to maintain the integrity of sequential data processing.
Look here for an example.
So, that’s it! Those are the 3 Types of Self-Attention Mechanisms, used in the Transformer architecture, that has revolutionized the world of NLP.
And remember, if you enjoyed this deep dive, follow me so you won’t miss out on future updates.
Clap and Share your thoughts below, if you want to see something specific.
Until next time, happy learning!
— Nikita Prasad
Reference
[1] Ashish Vaswani, et al. and team, “Attention is all you need”, 2017.
Self-Attention Networks : Beginners Friendly In-Depth Understanding was originally published in Level Up Coding on Medium, where people are continuing the conversation by highlighting and responding to this story.
This content originally appeared on Level Up Coding – Medium and was authored by Nikita Prasad