This content originally appeared on Level Up Coding – Medium and was authored by Rohit Sharma
There’s something profoundly satisfying about those rare moments when a research paper you once read becomes something you can actually run. Not a simulation, not a mockup — but a living, reasoning, executing system.
That’s what happened when I read Executable Code Actions Elicit Better LLM Agents by Xingyao Wang et al. and decided to build my own version of the proposed CodeAct agent. The paper described a simple but radical idea: instead of giving language models a fixed set of tools or APIs to call, what if the language of action itself was code?
A few hours later, I found myself watching an agent generate, execute, debug, and even train a machine-learning model — all by itself — inside a Streamlit app. Let’s unpack what that means and why it matters.
(Here is the link to the paper: https://arxiv.org/abs/2402.01030)
1⃣ The Paper — Executable Code Actions Elicit Better LLM Agents
The CodeAct paper asked a fundamental question:
“How can we expand an LLM agent’s action space to tackle real-world problems without hard-coding every possible tool?”
Traditional LLM agents act by emitting text or JSON commands that get routed to predefined APIs — a brittle pattern that limits flexibility. CodeAct unifies everything into one universal action space: Python code.
The agent generates code, executes it in a sandbox, observes results or errors, and uses those observations as feedback to self-improve. This turns the LLM into something closer to a runtime organism than a static responder.
Three key insights from the paper stood out:
- Code as Action: Python becomes the universal medium of interaction. Every API call, visualization, or reasoning step can be expressed in code.
- Self-Debugging Loop: Agents learn by reading their own stack traces and fixing themselves.
- Reduced Prompt Engineering: Because code execution provides ground-truth feedback, the model doesn’t need handcrafted prompts or external evaluators.
The authors demonstrated that this approach outperformed traditional JSON- or text-based action models by up to 20 % success rate on benchmark tasks.
2⃣ Implementing CodeAct
I wanted to see what this looks like in practice — so I built a working version.
At its heart lies one loop:
generate → execute → observe → self-debug
My implementation (codeact_core.py) wraps this loop with a safe execution layer and minimal guardrails:
- safe_exec() — runs arbitrary code, captures stdout/stderr, and auto-renders plots.
- summarize_result() — converts raw outputs into natural-language summaries using GPT-4o-mini.
- codeact_agent() — handles multi-turn reasoning, automatic retries, and self-correction.
Guardrails include:
- Always loading the Titanic dataset from a known path (data/titanic.csv).
- Preferring pandas + matplotlib for analytical tasks.
- Saving trained models automatically under model/.
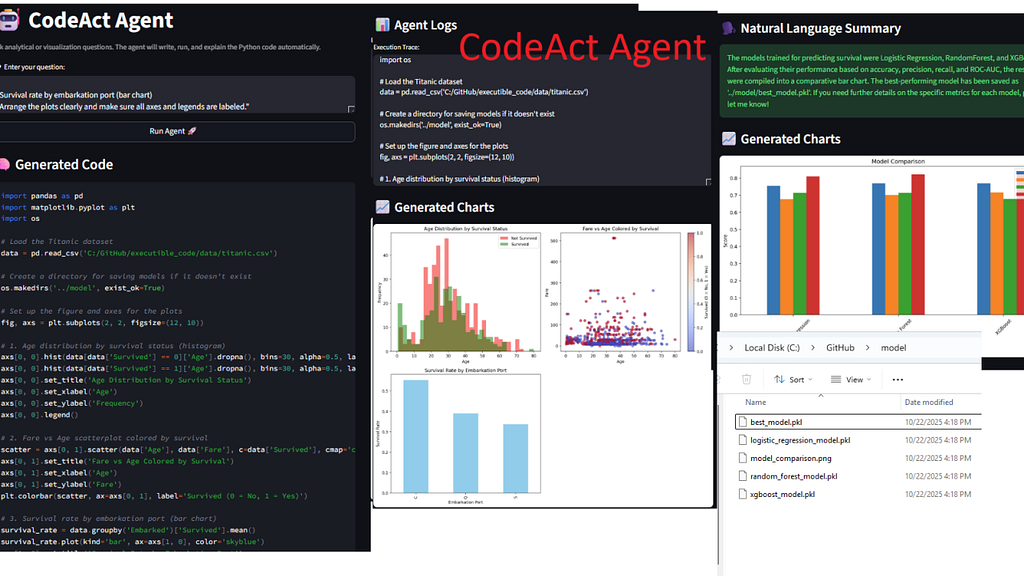
When wrapped with a small Streamlit front-end, this became an interactive “thinking sandbox”: you type a natural question — it writes, executes, debugs, and explains the code live.
For readers who want to see how each component interacts in detail, there’s a short Code Walkthrough section later that breaks down the full loop step by step.
3⃣ The Demo — Watching the Agent Think
Here are a few questions that reveal its emergent behavior.
For these experiments, I used the classic Titanic dataset — a well-known benchmark for survival prediction — to observe how the agent reasons, visualizes, and models real data.
 Demo 1 — Data Reasoning and Comparative Insight
Demo 1 — Data Reasoning and Comparative Insight
Prompt:
“Analyze the relationship between passenger class, gender, and survival rate. For each class, compute the survival percentage for males and females separately, and identify which subgroup had the highest survival advantage relative to their peers.”
 What the Agent Did
What the Agent Did
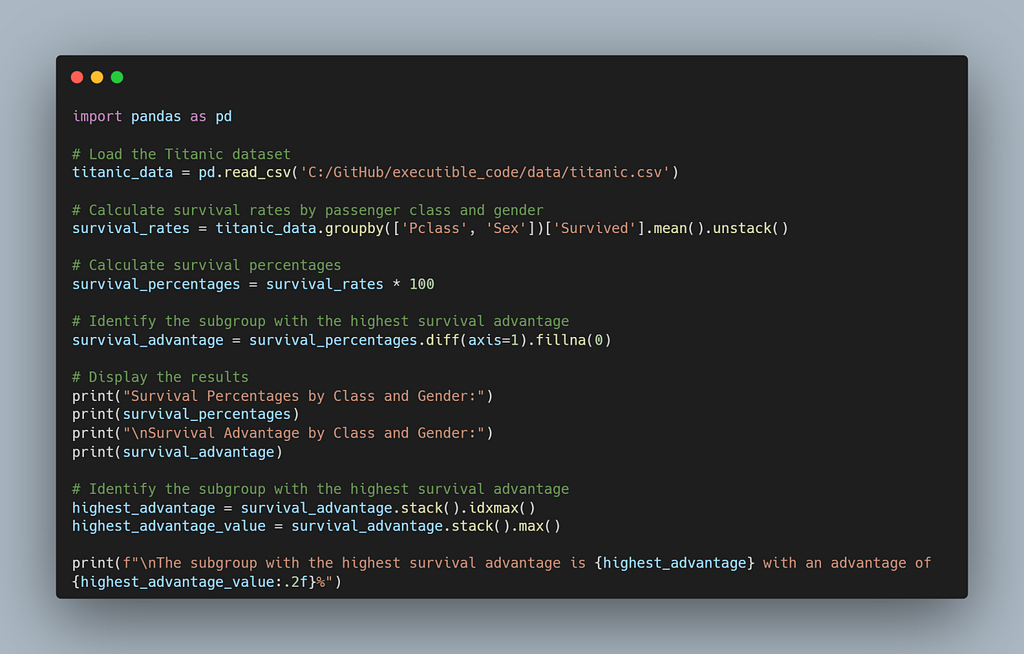
On the first attempt, the CodeAct agent generated a multi-step pandas workflow that:
- Loaded the Titanic dataset.
- Grouped data by Pclass and Sex to compute survival means.
- Converted survival rates to percentages for clarity.
- Compared male vs. female survival percentages within each class to measure “advantage.”
- Printed both the tabular results and the most advantaged subgroup.
Here’s the code it wrote — entirely on its own:
 Output
Output

 Why It Matters
Why It Matters
This example demonstrates several hallmark behaviors of CodeAct-style agents:
- Structured reasoning: it decomposed the question into aggregation, comparison, and ranking.
- Reproducibility: every step is transparent, auditable Python.
- Interpretability: both raw tables and a textual conclusion were produced automatically.
- One-shot success: no retries were needed — the reasoning loop converged in the first turn.
In short, the agent didn’t just query data; it analyzed it — performing the kind of multi-level comparison that would typically require manual setup in a notebook.
 Demo 2 — Autonomous Multi-Plot Visualization
Demo 2 — Autonomous Multi-Plot Visualization
Prompt:
“Create a set of visualizations showing survival patterns across different factors: — Age distribution by survival status (histogram) — Fare vs Age scatterplot colored by survival — Survival rate by embarkation port (bar chart) Arrange the plots clearly and make sure all axes and legends are labeled.”
What the Agent Did
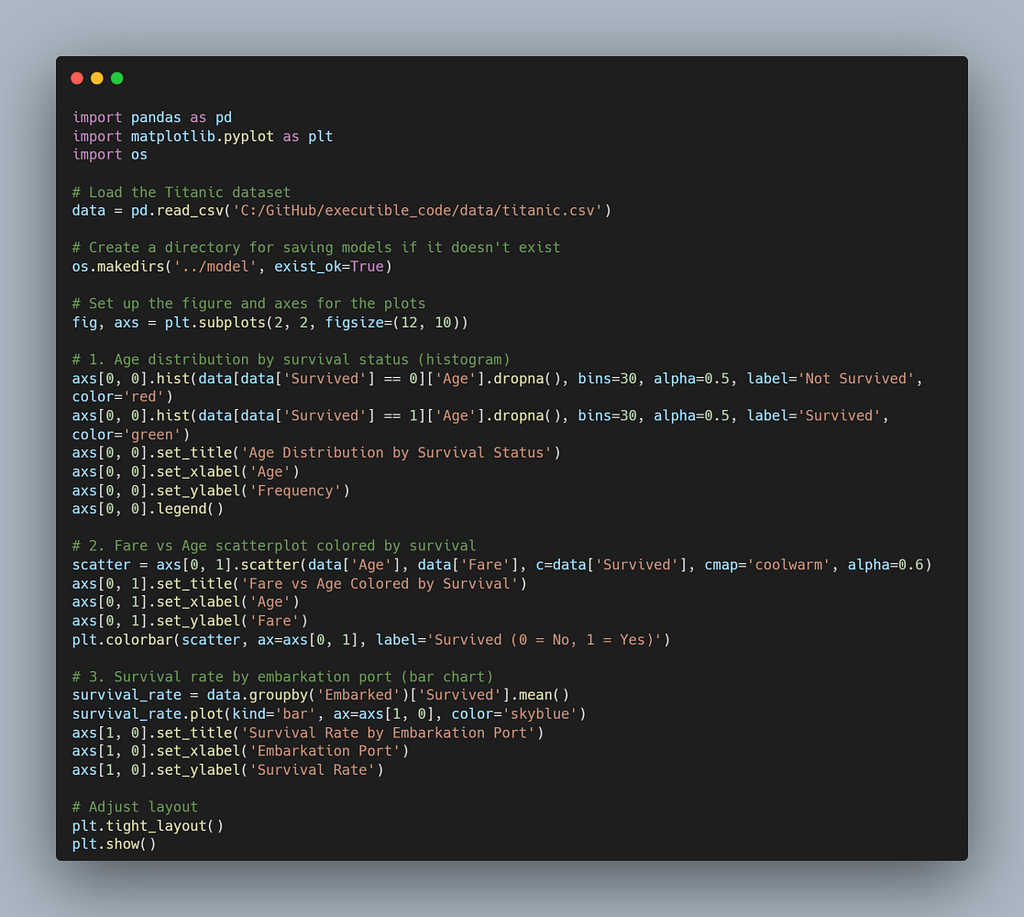
The CodeAct agent immediately recognized this as a multi-chart composition task and built a full 2×2 matplotlib grid — no template or helper library required. In one pass, it:
- Loaded the Titanic dataset.
- Created subplots to hold three different visualizations.
- Plotted:
- Added axis labels, titles, legends, and a colorbar for interpretability.
- Adjusted layout and displayed the composite figure.
Here’s the agent-generated code:
 Output
Output
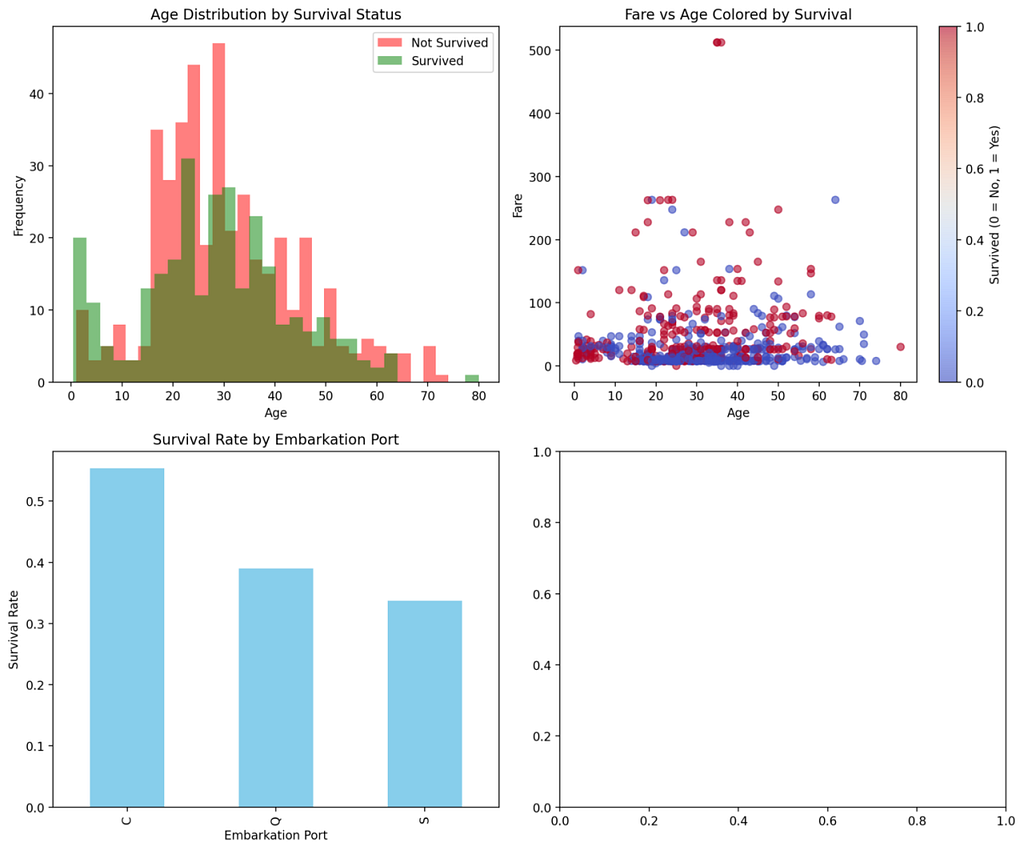
The agent successfully produced three coordinated visualizations:
- Top-left: Age histogram showing higher female survival concentration in the 20–40 range.
- Top-right: Fare-Age scatterplot where survivors (blue → red gradient) cluster at higher fares.
- Bottom-left: Bar chart showing Embarked = ‘C’ passengers with the highest average survival rate.
Why It Matters
This demo shows the agent’s ability to:
- Compose multiple visualization primitives (histograms, scatterplots, bar charts) within one execution cycle.
- Handle aesthetics and annotations autonomously -legends, titles, labels, and colorbars were all auto-generated.
- Use feedback-free reasoning: it structured a complex matplotlib workflow correctly on the first try.
In other words, the agent didn’t just answer a question — it built a full analytical dashboard in code, mirroring what a data scientist might construct manually in a notebook.
 Demo 3 — Autonomous Model Training and Evaluation
Demo 3 — Autonomous Model Training and Evaluation
Prompt:
“Train and evaluate three models to predict survival: Logistic Regression, Random Forest, and XGBoost (if available). Use Age, Fare, Pclass, and Sex as predictors after cleaning missing data. Report accuracy, precision, recall, and ROC-AUC for each model, then plot a comparative bar chart of all metrics across models and save the best model to ‘../model/best_model.pkl’.”
What the Agent Did
The CodeAct agent understood this as a multi-model ML workflow and, in a single pass, built a full training–evaluation pipeline:
- Data Preparation — Encoded gender, dropped missing rows, selected numeric features (Age, Fare, Pclass, Sex).
- Split Data — Used an 80/20 train–test split with a fixed random seed.
- Instantiated Three Models — LogisticRegression, RandomForestClassifier, and XGBClassifier.
- Trained and Evaluated Each — Computed Accuracy, Precision, Recall, and ROC-AUC scores.
- Saved Artifacts — Persisted each model to ../model/ and chose the best one (by highest ROC-AUC).
- Visualized Results — Generated a comparative bar chart across all metrics.
It performed every step autonomously — no pre-wired pipeline, no helper scripts.
 Generated Code
Generated Code

Results (Agent Output)
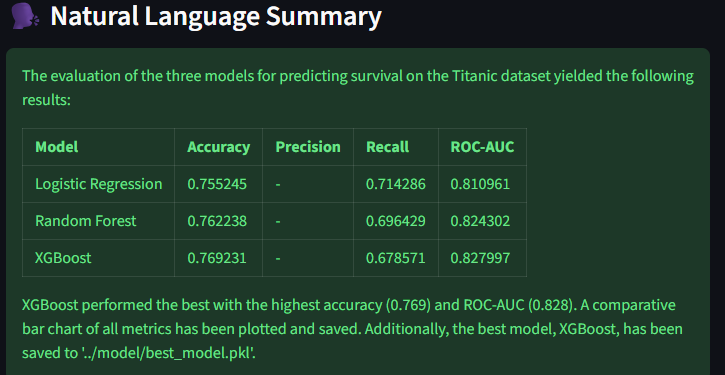
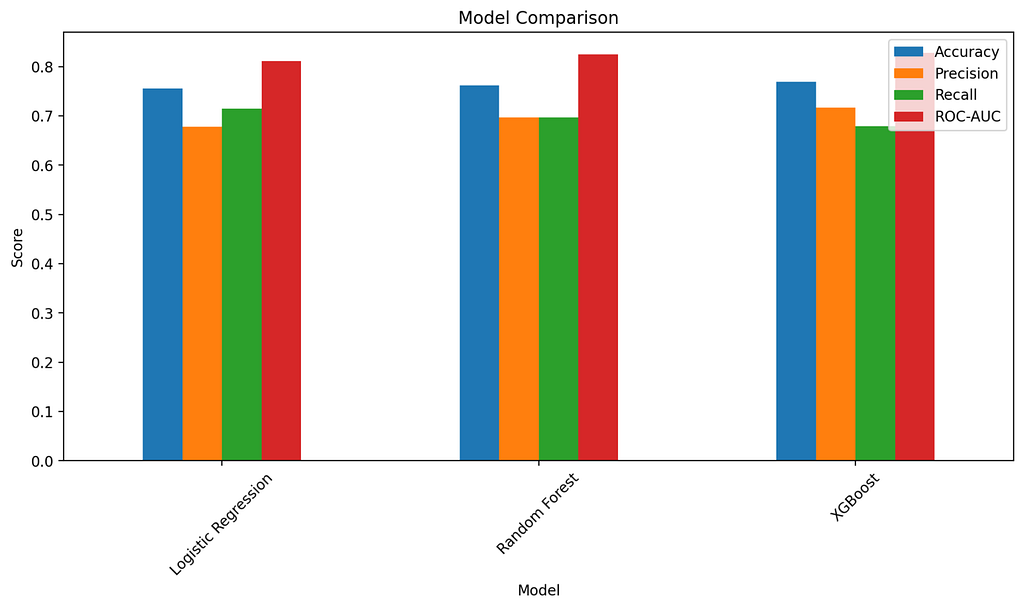
Generated Chart
The bar chart compares all metrics side-by-side across models, providing an immediate visual of performance parity and trade-offs.
Why It Matters
This final demo closes the loop on what the CodeAct framework enables:
- End-to-end autonomy — data prep → modeling → evaluation → artifact persistence, all from a natural language prompt.
- Self-contained reasoning — the agent planned the entire workflow without manual tool or schema definitions.
- Transparent ML operations — everything happened in auditable Python code, reproducible and inspectable.
This isn’t a hard-coded ML pipeline — it’s an agent that composed one on the fly, executed it, and evaluated it like a practitioner.
4⃣ Code Walkthrough — Inside the Agent Loop
For readers who want to look under the hood, here’s the complete implementation of the CodeAct loop. It’s composed of three key functions: safe_exec(), summarize_result(), and codeact_agent(). Together, they turn natural language into executable reasoning.
Overall Flow
At a high level, the process looks like this:
Prompt → Code → Execution → Feedback → Correction → Summary
The LLM generates Python code, the runtime executes it, and any exceptions flow back into the model as feedback for self-debugging. Successful outputs are then summarized into natural language for the user interface.
 Core Implementation
Core Implementation
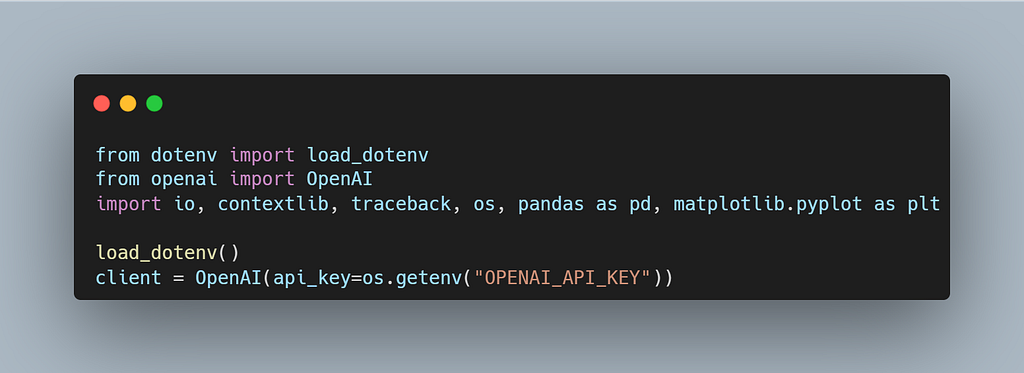
The agent uses gpt-4o-mini through the OpenAI SDK and loads credentials via environment variables — keeping it clean and portable.
 safe_exec() — Controlled Code Execution
safe_exec() — Controlled Code Execution
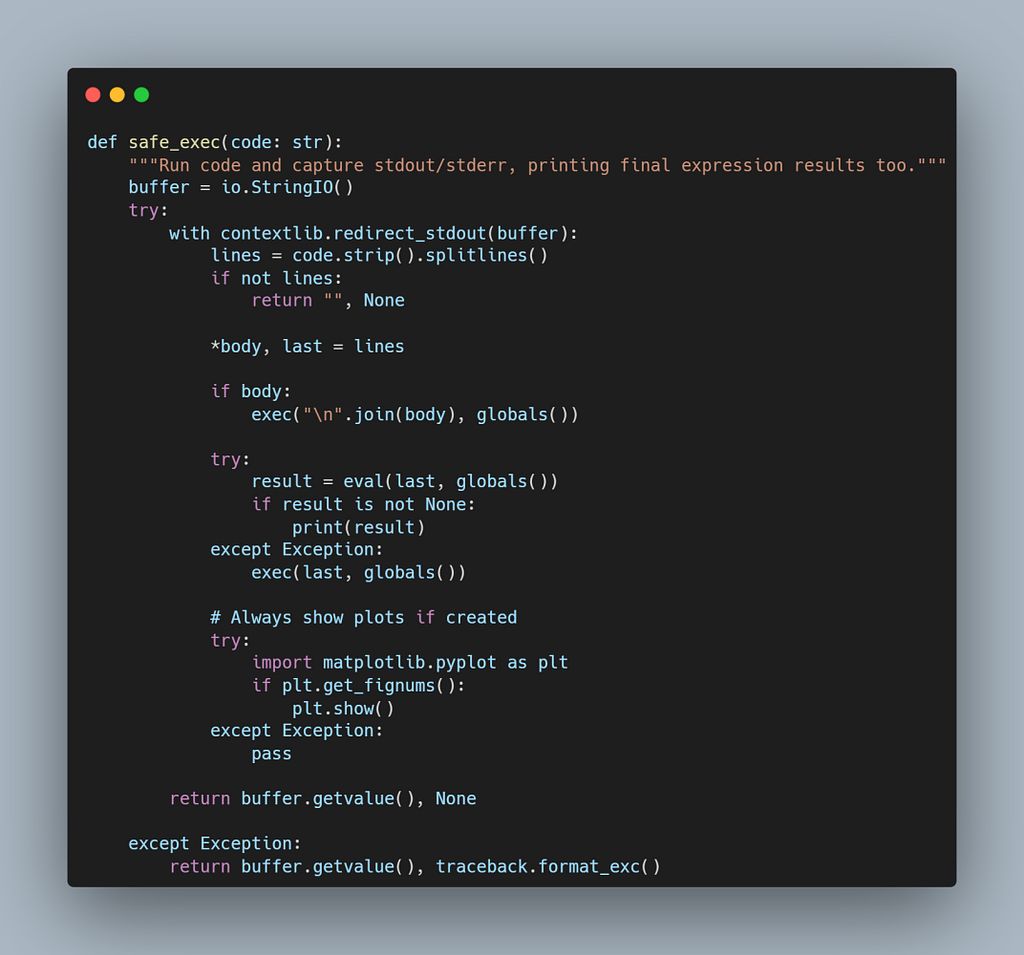
What it does
- Executes generated Python safely inside a redirected I/O buffer.
- Captures all printed output and exceptions for inspection.
- Automatically renders Matplotlib figures if created.
- Returns both the captured output and any traceback.
This acts as the environment layer in the CodeAct loop — the LLM’s execution sandbox.
 summarize_result() — Translating Raw Output into Language
summarize_result() — Translating Raw Output into Language
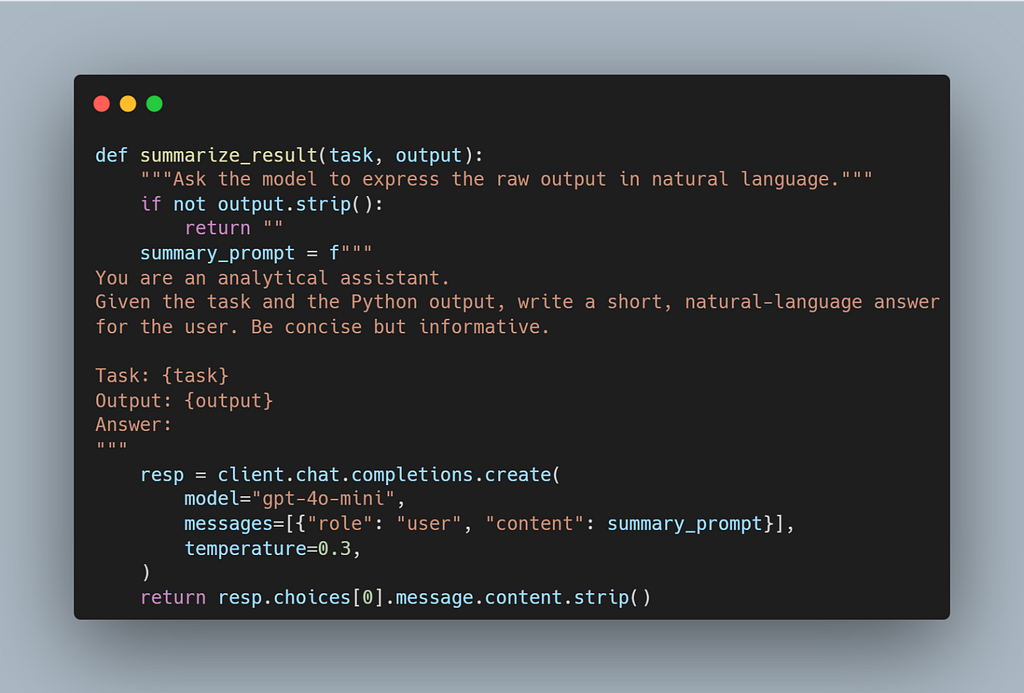
This function calls the model again to explain the computed output in plain English — bridging the gap between execution and interpretation.
 codeact_agent() — The Self-Improving Loop
codeact_agent() — The Self-Improving Loop

How it works
- Builds a contextual system prompt with embedded guardrails.
- Calls the LLM to generate Python code.
- Executes that code via safe_exec().
- If an error occurs, appends the traceback as a new user message and asks the LLM to fix its own code.
- Stops when successful or after three rounds.
- Summarizes the result and returns code, output, and logs for the Streamlit UI.
In other words, this is the living embodiment of generate → execute → observe → self-debug.
Why This Matters
This 70-line loop is the essence of CodeAct:
- It replaces rigid tool schemas with open-ended code reasoning.
- It fuses execution feedback directly into the language model’s thought process.
- It’s short, transparent, and extensible — the kind of minimal system that feels almost inevitable once you see it.
Extending the Loop
While already powerful, this architecture can be evolved further:
- Add memory: Maintain a lightweight state or variable context across turns to enable cumulative reasoning.
- Sandbox execution: Run code safely in an isolated subprocess or container to mitigate risks from arbitrary execution.
- Metric logging: Capture run statistics (turn count, error categories, success rate) for benchmarking and evaluation — similar to CodeAct’s own research harness.
These additions transform the minimal loop into a production-grade agent framework — one capable of introspection, persistence, and safe autonomy.
5⃣ Takeaways — Agents That Write Their Own Tools
The CodeAct framework — and this minimal implementation of it — redefines what it means for a model to use tools. Instead of relying on predefined APIs or rigid JSON-based schemas, the agent treats code itself as the tool. Every action, computation, and visualization is expressed through Python — the universal language of reasoning and execution.
Key Lessons
- Code is the ultimate action space: It unifies every possible operation — data analysis, plotting, model training, or file manipulation — under one expressive medium.
- Self-debugging is self-learning: The moment an agent reads its own traceback and fixes it, it crosses from scripted automation into autonomous improvement.
- Less prompting, more feedback: Execution feedback becomes the grounding signal. The model doesn’t need a handcrafted chain of tools — it learns directly from the environment’s response.
- Transparency over abstraction: Every decision the agent makes is visible in executable Python — you can audit, reproduce, and extend it with zero black boxes.
Why It Matters
This small system demonstrates how a language model can plan, act, and reflect entirely through code — reasoning not just in words but through execution. It’s a glimpse into a future where:
- Agents don’t call tools; they create them.
- Tool orchestration gives way to code synthesis and feedback-driven autonomy.
- The boundary between “developer” and “agent” begins to dissolve.
 Looking Ahead
Looking Ahead
The next frontier lies in scaling this design: adding persistent memory, secure sandboxes, evaluative metrics, and collaborative multi-agent workflows. But even this compact loop — a few dozen lines of code — embodies a profound shift:
Agents no longer wait for us to define their capabilities. They can write, test, and evolve their own tools — one execution at a time.
When Research Turns Real: Building a Working Agent from the CodeAct Paper was originally published in Level Up Coding on Medium, where people are continuing the conversation by highlighting and responding to this story.
This content originally appeared on Level Up Coding – Medium and was authored by Rohit Sharma