This content originally appeared on Level Up Coding – Medium and was authored by Julian Yip
Unlocking the value of non-textual contents in your knowledge base

If you’ve ever tried building a RAG (Retrieval-Augmented Generation) application, you’re likely familiar with the challenges posed by tables and images. This article explores how to tackle these formats using Vision Language Models, specifically with the ColPali model.
But first, what exactly is RAG — and why do tables and images make it so difficult?
RAG and parsing
Imagine you’re faced with a question like:
What’s the our company’s policy for handling refund?
A foundational LLM (Large Language Model) probably won’t be able to answer this, as such information is company-specific and typically not included in the model’s training data.
That’s why a common approach is to connect the LLM to a knowledge base — such as a SharePoint folder containing various internal documents. This allows the model to retrieve and incorporate relevant context, enabling it to answer questions that require specialized knowledge. This technique is known as Retrieval-Augmented Generation (RAG), and it often involves working with documents like PDFs.
However, extracting the right information from a large and diverse knowledge base requires extensive document preprocessing. Common steps include:
- Parsing: Parsing documents into texts and images, often assisted with Optical Character Recognition (OCR) tools like Tesseract. Tables are most often converted into texts
- Structure Preservation: Maintain the structure of the document, including headings, paragraphs, by converting the extracted text into a format that retains context, such as Markdown
- Chunking: Splitting or merging text passages, so that the contexts can be fed into the context window without causing the passages come across as disjointed
- Enriching: Provide extra metadata e.g. extract keyword or provide summary to the chunks to ease discovery. Optionally, to also caption images with descriptive texts via multimodal LLM to make images searchable
- Embedding: Embed the texts (and potentially the images too with multimodal embedding), and store them into a vector DB
As you can imagine, the process is highly complicated, involves a lot of experimentation, and is very brittle. Worse yet, even if we tried to do it as best as we could, this parsing might not actually work after all.
Why parsing often falls short?
Tables and image often exist in PDFs. The below image shows how they are typically parsed for LLM’s consumption:

- Texts are chunked
- Tables are turned into texts, whatever contained within are copied without preserving table boundaries
- Images are fed into multimodal LLM for text summary generation, or alternatively, the original image is fed into multimodal embedding model without needing to generate a text summary
However, there are two inherent issues with such traditional approach.
#1. Complex tables cannot be simply be interpreted as texts
Taking this table as an example, we as human would interpret that a temperature change of >2˚C to 2.5˚C’s implication on Health is A rise of 2.3˚C by 2080 puts up to 270 million at risk from malaria

However, if we turn this table into a text, it would look like this: Temperature change Within EC target <(2˚C) >2˚C to 2.5˚C >3C Health Globally it is estimated that A rise of 2.3oC by 2080 puts A rise of 3.3oC by 2080 an average temperature rise up to 270 million at risk from would put up to 330…
The result is a jumbled block of text with no discernible meaning. Even for a human reader, it’s impossible to extract any meaningful insight from it. When this kind of text is fed into a Large Language Model (LLM), it also fails to produce an accurate interpretation.
#2. Disassociation between texts and images
The description of the image is often included in texts and they are inseparable from one another. Taking the below as an example, we know the chart represents the “Modelled Costs of Climate Change with Different Pure Rate of Time Preference and declining discount rate schemes (no equity weighting)”

However, as this is parsed, the image description (parsed text) will be disassociated with the image (parsed chart). So we can expect, during RAG, the image would not be retrieved as input when we raise a question like “what’s the cost of climate change?”

So, even if we attempt to engineer solutions that preserve as much information as possible during parsing, they often fall short when faced with real-world scenarios.
Given how critical parsing is in RAG applications, does this mean RAG agents are destined to fail when working with complex documents? Absolutely not. With ColPali, we have a more refined and effective approach to handling them.
What’s ColPali?
The core premise of ColPali is simple: Human read PDF as pages, not “chunks”, so it makes sense to treat PDF as such: Instead of going through the messy process of parsing, we just turn the PDF pages into images, and use that as context for LLM to provide an answer.

Now, the idea of embedding images using multimodal models isn’t new — it’s a common technique. So what makes ColPali stand out? The key lies in its inspiration from ColBERT, a model that embeds inputs into multi-vectors, enabling more precise and efficient search.
Before diving into ColPali’s capabilities, let me briefly digress to explain what ColBERT is all about.
ColBERT: Granular, context-aware embedding for texts
ColBERT is a text embedding and reranking technique that leverage on multi-vectors to enhance search accuracy for texts.
Let’s consider this case: we have this question: is Paul vegan?, we need to identify which text chuck contains the relevant information.
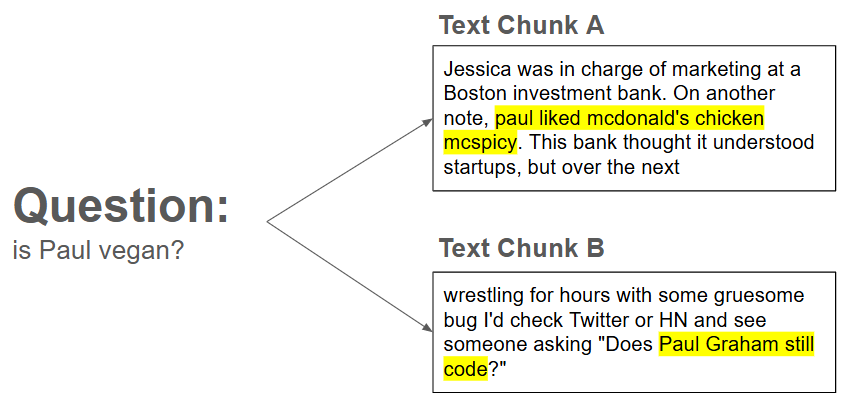
Ideally, we should identify Text Chunk A as the most relevant one. But if we use a single-vector embedding model (text-ada-002), it will return Text Chunk B instead.
The reason lies in how single-vector bi-encoders — like text-ada-002 — operate. They attempt to compress an entire sentence into a single vector, without encoding individual words in a context-aware manner. In contrast, ColBERT embeds each word with contextual awareness, resulting in a richer, multi-vector representation that captures more nuanced information.

ColPali: ColBERT’s brother for handling document-like images
ColPali follows a similar philosophy but applies it to document-like images. Just as ColBERT breaks down text and embeds each word individually, ColPali divides an image into patches and generates embeddings for each patch. This approach preserves more of the image’s contextual detail, enabling more accurate and meaningful interpretation.

Apart from higher retrieval accuracy, benefits of ColPali includes:
- Explainability: ColPali enables word-level comparison between the query and individual image patches of a document. This allows us to clearly understand and justify why a particular document is deemed more relevant.
- Reduced Development Effort & Greater Robustness: By eliminating the need for complex preprocessing pipelines — such as chunking, OCR, and layout parsing — ColPali significantly reduces development time and minimizes potential points of failure.
- Performance Gains: Embedding and retrieval processes are faster, resulting in improved overall system responsiveness.
Now you know what ColPali is, let’s dive into the code and see if ColPali can resolve the challenges we mentioned earlier!
Illustration
My code can be found in my Github. A few words about it:
- Instance: Running the code requires a machine with A100 GPU
- Embedding model: ColPali has a number of variants, I am using vidore/colqwen2-v0.1 for demonstration. You can refer to the leaderboard here and switch to other models
- Agent:
– LLM: I am using OpenRouter to consume LLM, and the agent is powered by GPT-4o. You can substitute it with any multimodal LLM that can take image as input
– Orchestration: LangGraph is used to develop the agent - Library used for converting PDF into images: pdf2image which is a wrapper for poppler. So please make sure you also have poppler installed
- Sample data: “The Impacts and Costs of Climate Change” written by Paul Watkiss et al, which is publicly available here
Results
The code is pretty straightforward, so I will jump into conclusion instead: How well can ColPali deal with the problems we have seen in the “Why parsing often falls short?” section?
#1. Complex tables cannot be simply be interpreted as texts
Question: What’s the health impact if temperature rises above pre-industrial level by 3 degrees?
Answer: If the temperature rises above pre-industrial levels by 3 degrees Celsius, the health impact would be significant. Specifically, it is estimated that by the 2080s, up to 330 million people would be at risk from malaria. This is a substantial increase compared to the 1920s, where the number at risk was between 50 to 100 million.
This is correctly referred from this table in the PDF!

#2. Disassociation between texts and images
Question: What’s the modelled cost of climate change, according to the Greenbook declining model?
Answer: According to the Greenbook declining model, the modelled cost of climate change is 7.2 Euro/tCO2
The correct answer should be 7.4 Euro/tCO2, but we can see it is close to correct!

Conclusion
Traditional RAG pipelines struggle with non-textual content. ColPali treats each PDF page as an image, allowing it to process visual layouts, tables, charts, and embedded graphics — formats that standard text parsers often distort or ignore.
ColPali brings vision-language intelligence to RAG, making it far more capable of handling the messy, multimodal reality of enterprise documents.
*Unless otherwise noted, all images are by the author
Bringing vision-language intelligence to RAG with ColPali was originally published in Level Up Coding on Medium, where people are continuing the conversation by highlighting and responding to this story.
This content originally appeared on Level Up Coding – Medium and was authored by Julian Yip