This content originally appeared on Level Up Coding – Medium and was authored by Senthil E

From Architecture to Implementation: A Complete Guide to Building an Intelligent Repository Analysis System
Introduction

The Challenge of Modern Codebases
Modern software repositories have grown increasingly complex, often containing thousands of files, multiple interdependent modules, and extensive documentation across various formats. Consider OpenAI’s Whisper repository, which includes:
- Multiple Python modules and packages
- Complex ML model implementations
- Documentation in various formats (Markdown, docstrings, comments)
- Configuration files and environment settings
- Test suites and examples
Developers and teams face several critical challenges:
- Knowledge Discovery: Finding specific implementation details or documentation quickly
- Context Understanding: Grasping how different components interact
- Configuration Management: Tracking environment variables and dependencies
- Documentation Navigation: Accessing relevant information across multiple file formats
Whisper Repository AI Assistant: A Simple Overview
What is it?
The Whisper Repository AI Assistant is a tool that helps developers understand and work with code repositories more easily. Think of it as an intelligent assistant that can read, understand, and answer questions about code repositories, starting with OpenAI’s Whisper project as an example.








Core Components and How They Work
1. Data Ingestion System
- What it does: This is like a smart reader that goes through the entire repository
- Handles:
- Reading Python code files
- Processing documentation files
- Extracting important information like functions, classes, and comments
- Understanding environment variables and configuration settings
- Think of it as: A careful reader who takes notes about everything important in the repository
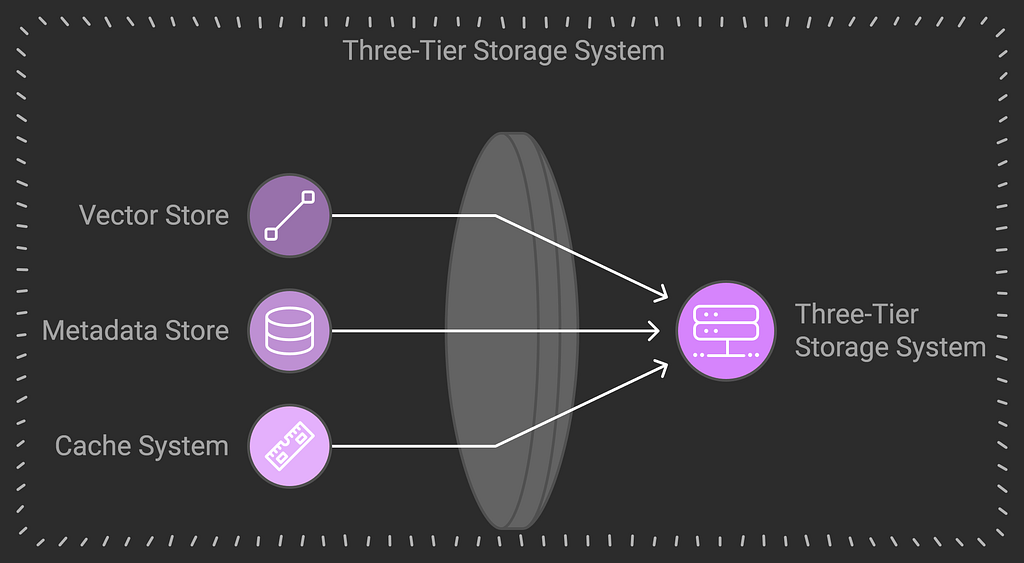
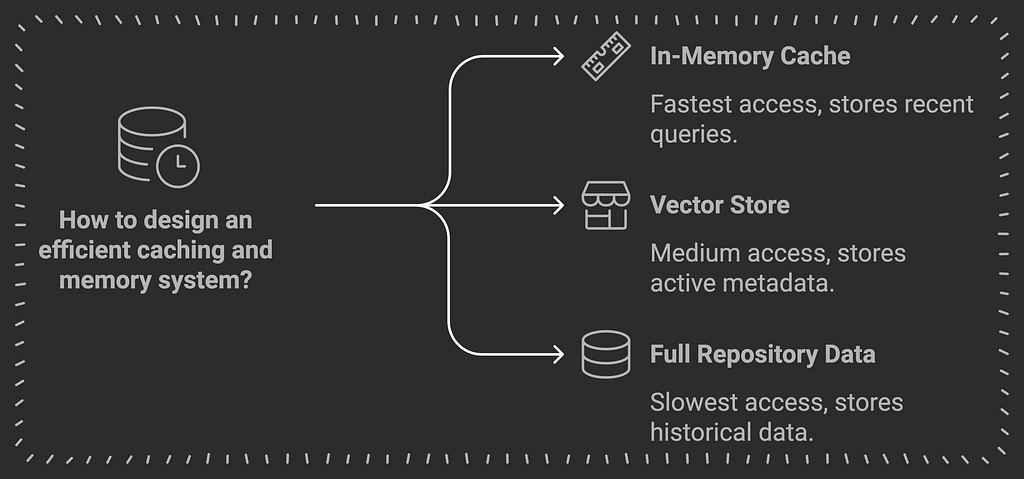
2. Storage System
- What it does: Organizes and stores all the processed information for quick access
- Contains:
- Vector Store (ChromaDB): Stores text in a way that makes semantic search possible
- Metadata Store (SQLite): Keeps track of structured information
- Cache System: Remembers recent queries for faster responses
- Think of it as: A librarian who organizes books (code) and knows exactly where to find any information
3. AI Processing Pipeline
- What it does: Handles user questions and generates accurate answers
- Components:
- Query Processor: Understands what the user is asking
- Context Retriever: Finds relevant information from storage
- Response Generator: Creates accurate, helpful answers using GPT-4
- Think of it as: A knowledgeable expert who can answer questions about the code
4. User Interface
- What it does: Provides an easy way for users to interact with the system
- Features:
- Chat interface for asking questions
- Code viewer for displaying relevant code snippets
- Simple, clean design using Streamlit
- Think of it as: The front desk where users can ask questions and get answers

How Information Flows Through the System
- Initial Setup:
- The system clones the repository
- Processes all files and extracts important information
- Stores everything in organized databases
2. When a User Asks a Question:
- Question goes to the Query Processor
- System finds relevant information from storage
- AI generates a helpful response using the context
- User gets an answer with relevant code snippets and explanations
3. Behind the Scenes:
- Uses RAG (Retrieval Augmented Generation) to ensure accurate answers
- Maintains context awareness across conversations
- Verifies sources and citations
- Optimizes performance through caching
Key Features
- Smart Understanding:
- Understands both code and documentation
- Can explain complex code in simple terms
- Provides relevant examples and context
2. Accurate Responses:
- Uses RAG to ensure answers are based on actual repository content
- Provides source citations
- Verifies information before responding
3. Performance Optimized:
- Fast response times through efficient storage
- Smart caching for common queries
- Handles large repositories effectively
4.User Friendly:
- Simple chat interface
- Code highlighting and formatting
- Clear and concise answers
What Makes It Special
- Context Awareness: Understands the entire repository as a whole, not just individual files
- Accuracy: Uses advanced RAG implementation to ensure responses are accurate and based on actual code
- Efficiency: Optimized for performance with smart caching and storage systems
- Flexibility: Can be adapted for other repositories and codebases
Real-World Benefits
- For Developers:
- Quickly understand new codebases
- Find specific implementations
- Understand how different parts work together
2. For Teams:
- Easier onboarding of new team members
- Faster code reviews
- Better documentation understanding
3. For Organizations:
- Reduced time spent understanding code
- Better knowledge sharing
- Improved code maintenance
This system brings together modern AI capabilities, efficient data storage, and user-friendly design to make code repositories more accessible and understandable. It’s like having an expert who has read and understood the entire codebase, ready to answer questions and provide insights at any time.
We can customize it to any repository, including the Whisper repository.
GitHub – openai/whisper: Robust Speech Recognition via Large-Scale Weak Supervision
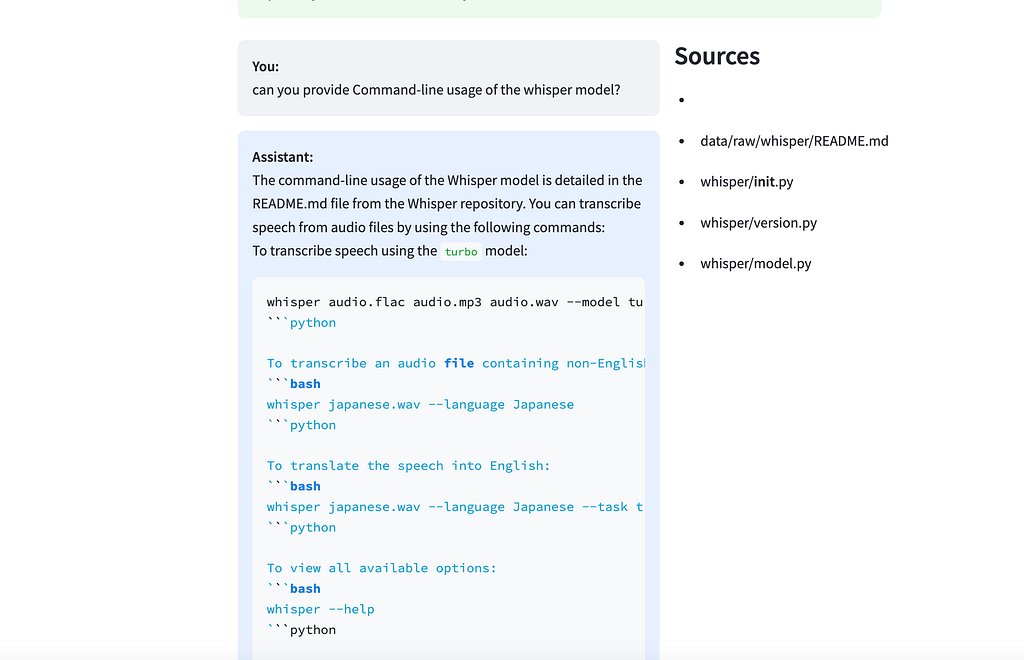
Example interaction:
# User Query:
"How does the audio processing pipeline work in Whisper?"
# AI Agent Response:
"""Based on the repository content, the audio processing pipeline in Whisper is
implemented in audio.py and consists of several key steps:
1. Load and pad/trim the audio to 30-second segments
2. Convert to mono channel if needed
3. Resample to 16kHz
4. Extract mel spectrogram features
Key implementation from audio.py:
```python
def load_audio(file: str, sr: int = SAMPLE_RATE):
# ... implementation details
return audio
def log_mel_spectrogram(audio: Union[str, np.ndarray],
n_mels: int = N_MELS):
# ... mel spectrogram extraction
return mel
Source: whisper/audio.py """
### Key Features and Capabilities
1. **Intelligent Code Analysis**
- AST-based code parsing
- Function and class relationship mapping
- API endpoint detection
- Environment variable tracking
2. **Multi-format Documentation Processing**
- Markdown files
- Python docstrings
- Inline comments
- Configuration files
3. **Context-Aware Search**
- Vector-based semantic search
- Metadata-enhanced retrieval
- Source attribution
- Relevance ranking
4. **Interactive Query Processing**
- Natural language understanding
- Code-specific entity recognition
- Technical context preservation
- Source verification
### Technical Goals and Design Principles
1. **Accuracy First**
```python
# Example of strict context verification
async def generate_response(self, query: str, context: Dict[str, Any]) -> Dict[str, Any]:
if not self._verify_context_quality(context):
return self._create_insufficient_context_response(query)
response = await self._generate_llm_response(query, context)
if not self._verify_response_uses_context(response, context):
return self._add_context_warning(response)
System Overview Diagram

Configuration Example
# config.yaml
storage:
vector_store:
type: "chromadb"
persist_directory: "./data/embeddings"
embedding_model: "text-embedding-3-small"
metadata_store:
type: "sqlite"
db_path: "./data/metadata.db"
ai_processing:
model: "gpt-4-0125-preview"
temperature: 0.7
max_tokens: 2000
data_ingestion:
file_types: [".py", ".md", ".txt"]
batch_size: 5
parser_settings:
parse_docstrings: true
extract_inline_comments: true
This system represents a significant step forward in repository interaction, combining the power of modern AI with careful software engineering principles to create a tool that makes complex codebases more accessible and understandable.
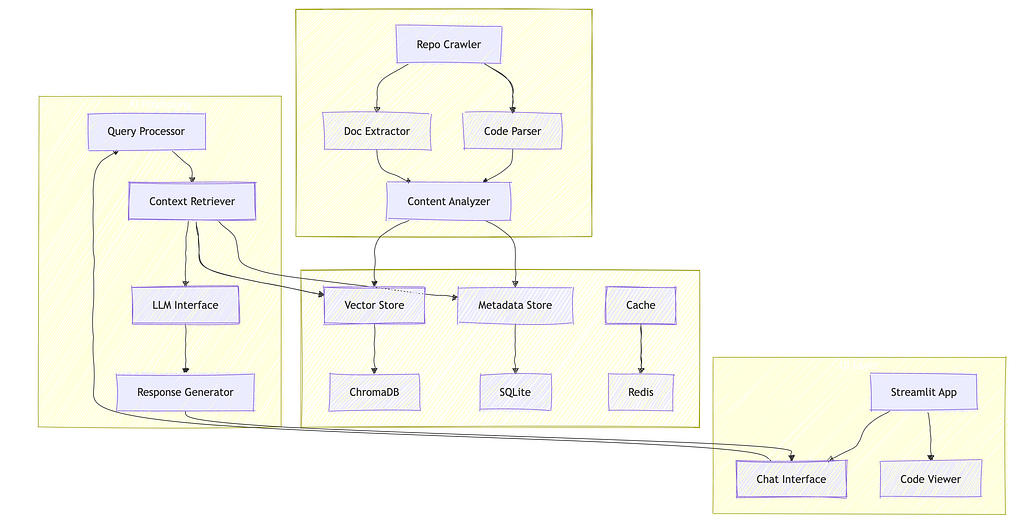
System Architecture
High-Level Overview
The Whisper Repository AI Agent follows a modular, component-based architecture designed for flexibility, maintainability, and performance. The system is built around four primary subsystems that interact through well-defined interfaces.
Component-Based Architecture
Data Flow and Interaction Patterns
- Repository Processing Flow
# Example from setup_whisper_assistant.py
async def main():
# Initialize components
storage = StorageManager(
persist_directory='./data/embeddings',
metadata_db_path='./data/metadata.db',
preserve_data=True
)
ingestion = DataIngestion(
repo_url="https://github.com/openai/whisper",
local_path="./data/raw/whisper"
)
# Process Repository
results = ingestion.process_repository()
processed_content = await process_repository_content(
content_analyzer,
results
)
# Store Results
await store_all_data(storage, results, processed_content)
2. Query Processing Flow
# Example from ai_processing/__init__.py
async def process_query(self, query: str) -> Dict[str, Any]:
try:
# Process query
processed_query = self.query_processor.process_query(query)
# Retrieve context
context = self.context_retriever.get_context(processed_query)
# Generate response
llm_response = await self.llm_interface.generate_response(
query,
context,
processed_query
)
# Format final response
return self.response_generator.generate_response(
llm_response,
processed_query,
context
)
except Exception as e:
return self._create_error_response(query, str(e))
Key Subsystems and Responsibilities
- Data Ingestion Subsystem
- Repository cloning and updating
- Code parsing and analysis
- Documentation extraction
- Content preprocessing
2. Storage Subsystem
- Vector embeddings management
- Metadata storage
- Cache management
- Data persistence
3.AI Processing Subsystem
- Query understanding
- Context retrieval
- LLM integration
- Response generation
4. UI Subsystem
- User interaction
- Response visualization
- Code display
- Session management
Module-wise File Breakdown
1. Storage Module (`src/storage/`)
`vector_store.py`
- Purpose: Manages vector embeddings and semantic search functionality
- Key Features:
- Implements ChromaDB integration
- Handles document embeddings
- Manages semantic search operations
- Stores code snippets and documentation
- Optimizes search performance
- Handles batch operations for embeddings
`metadata_store.py`
- Purpose: Manages structured data and relationships
- Key Features:
- SQLite database management
- Stores API information
- Manages environment variables
- Handles file metadata
- Maintains repository information
- Implements query optimization
`cache.py`
- Purpose: Implements caching system for improved performance
- Key Features:
- Manages response caching
- Implements cache invalidation
- Handles memory optimization
- Provides cache statistics
- Implements TTL management
- Optimizes frequent queries
`enhanced_storage.py`
- Purpose: Provides advanced storage features and optimizations
- Key Features:
- Advanced content storage
- Enhanced retrieval mechanisms
- Storage optimization strategies
- Batch processing capabilities
- Custom collection management
2. AI Processing Module (`src/ai_processing/`)
`query_processor.py`
- Purpose: Handles query analysis and processing
- Key Features:
- Query classification
- Entity extraction
- Intent recognition
- Query optimization
- Search parameter generation
- Context determination
`context_retriever.py`
- Purpose: Manages context gathering and relevance
- Key Features:
- Context extraction
- Relevance scoring
- Source verification
- Context ranking
- Content filtering
- Context optimization
`llm_interface.py`
- Purpose: Manages interaction with GPT-4
- Key Features:
- LLM integration
- Prompt management
- Response handling
- Error recovery
- Token optimization
- Context window management
`response_generator.py`
- Purpose: Handles response creation and formatting
- Key Features:
- Response formatting
- Source attribution
- Code snippet formatting
- Quality validation
- Response optimization
- Citation management
`text_content_retriever.py`
- Purpose: Specializes in text content processing
- Key Features:
- Text extraction
- Content processing
- Markdown handling
- Documentation parsing
- Content organization
3. Data Ingestion Module (`src/data_ingestion/`)
`repo_crawler.py`
- Purpose: Handles repository access and file discovery
- Key Features:
- Repository cloning
- File system traversal
- File type detection
- Update management
- Path handling
`code_parser.py`
- Purpose: Analyzes and processes code files
- Key Features:
- AST parsing
- Code structure analysis
- Function extraction
- Class analysis
- Import detection
- Documentation extraction
Extractors (`src/data_ingestion/extractors/`)
`api_extractor.py`
- Purpose: Extracts API-related information
- Key Features:
- API endpoint detection
- Parameter extraction
- Return type analysis
- API documentation parsing
`doc_extractor.py`
- Purpose: Handles documentation extraction
- Key Features:
- Documentation parsing
- Comment extraction
- Markdown processing
- Section organization
`env_extractor.py`
- Purpose: Manages environment variable detection
- Key Features:
- Environment variable detection
- Default value extraction
- Requirement analysis
- Configuration parsing
4. UI Module (`src/ui/`)
`app.py`
- Purpose: Main application interface
- Key Features:
- Application setup
- Route management
- State management
- Error handling
- Session management
Components (`src/ui/components/`)
`chat.py`
- Purpose: Implements chat interface
- Key Features:
- Message handling
- Chat history
- User interaction
- Message formatting
`code_viewer.py`
- Purpose: Handles code display
- Key Features:
- Code highlighting
- Snippet display
- Documentation viewing
- Source navigation
Utils (`src/ui/utils/`)
`formatting.py`
- Purpose: Handles content formatting
- Key Features:
- Text formatting
- Code formatting
- Response styling
- Layout management
5. Core Configuration Files
`config.py`
- Purpose: Manages system configuration
- Key Features:
- Configuration loading
- Environment management
- Settings validation
- Default configurations
`setup_whisper_assistant.py`
- Purpose: Handles initial setup
- Key Features:
- System initialization
- Dependency setup
- Resource configuration
- Environment setup
Each module works together to create a cohesive system:
1. Data Ingestion processes the repository
2. Storage maintains organized access to information
3. AI Processing handles intelligent query processing
4. UI provides user interaction
The modules are designed to be:
- Modular and independent
- Easy to maintain
- Well-documented
- Performance-optimized
- Scalable
Core Components
Data Ingestion System
# src/data_ingestion/__init__.py
class DataIngestion:
def __init__(self, repo_url: str, local_path: str):
self.crawler = RepoCrawler(repo_url, local_path)
self.parser = CodeParser()
self.api_extractor = APIExtractor()
self.env_extractor = EnvExtractor()
self.doc_extractor = DocExtractor()
def process_repository(self) -> dict:
results = {
'files': [],
'apis': [],
'env_vars': [],
'documentation': []
}
python_files = self.crawler.get_file_list(['.py'])
for file_path in python_files:
# Process each file
doc_result = self.doc_extractor.extract_documentation(file_path)
code_structure = self.parser.parse_file(file_path)
apis = self.api_extractor.extract_apis(file_path)
env_vars = self.env_extractor.extract_env_vars(file_path)
# Aggregate results
results['files'].append({
'path': str(file_path),
'structure': code_structure,
'content': doc_result.get('content', {})
})
results['apis'].extend(apis)
results['env_vars'].extend(env_vars)
results['documentation'].append(doc_result)
return results
Storage Layer
# src/storage/__init__.py
class StorageManager:
def __init__(
self,
persist_directory: str,
metadata_db_path: str,
preserve_data: bool = True
):
self.vector_store = VectorStore(persist_directory)
self.metadata_store = MetadataStore(
metadata_db_path,
preserve_data
)
def store_repository_data(self, data: Dict[str, Any]):
# Store code snippets
self.vector_store.add_code_snippets(data['files'])
# Store documentation
self.vector_store.add_documentation(data['documentation'])
# Store metadata
self.metadata_store.store_env_variables(data['env_vars'])
self.metadata_store.store_api_metadata(data['apis'])
AI Processing Pipeline
# src/ai_processing/__init__.py
class AIProcessor:
def __init__(self, storage_manager, openai_api_key: str):
self.query_processor = QueryProcessor()
self.context_retriever = ContextRetriever(storage_manager)
self.llm_interface = LLMInterface(openai_api_key)
self.response_generator = ResponseGenerator()
User Interface
# src/ui/app.py
class WhisperAssistantUI:
def __init__(self):
self._verify_data_exists()
self._initialize_session_state()
self._setup_components()
def render(self):
st.title("Whisper Repository Assistant 🤖")
col1, col2 = st.columns([2, 1])
with col1:
self._render_chat_interface()
with col2:
self._render_code_viewer()

Integration Points
- Storage Integration
# Example configuration
storage_config = {
'vector_store': {
'engine': 'chromadb',
'embedding_model': 'text-embedding-3-small',
'dimensions': 1536
},
'metadata_store': {
'engine': 'sqlite',
'preserve_data': True
},
'cache': {
'engine': 'redis',
'ttl': 3600
}
}
2. LLM Integration
# src/ai_processing/llm_interface.py
class LLMInterface:
async def generate_response(
self,
query: str,
context: Dict[str, Any],
processed_query: Dict[str, Any]
) -> Dict[str, Any]:
system_prompt = self._construct_system_prompt(
processed_query['query_type']
)
user_prompt = self._construct_user_prompt(
query,
context,
processed_query
)
response = await self.client.chat.completions.create(
model="gpt-4-0125-preview",
messages=[
{"role": "system", "content": system_prompt},
{"role": "user", "content": user_prompt}
],
temperature=0.7,
max_tokens=2000
)
return self._process_response(response, context)

3. Data Ingestion and Processing
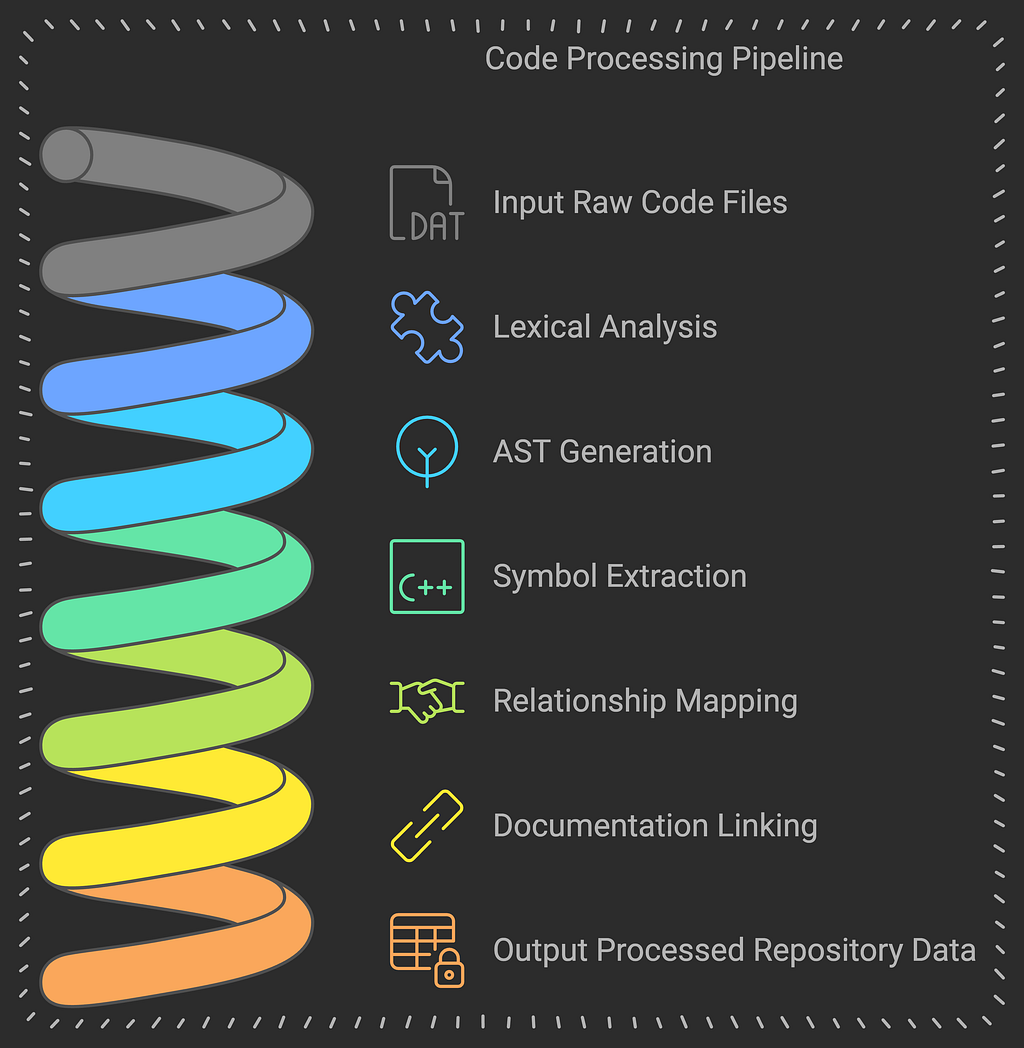
3.1 Repository Analysis
The repository analysis system employs sophisticated parsing and analysis techniques to extract meaningful information from codebases. Let’s dive into each component:
Code Parsing and AST Analysis
The system uses Python’s built-in ast module for parsing and analyzing code structure. Here's the implementation:
# src/data_ingestion/code_parser.py
class CodeParser:
def __init__(self):
self.logger = logging.getLogger(__name__)
def parse_file(self, file_path: Path) -> Dict[str, Any]:
"""Parse a Python file and extract comprehensive information."""
try:
with open(file_path, 'r', encoding='utf-8') as f:
content = f.read()
tree = ast.parse(content)
return {
'raw_content': content,
'file_path': str(file_path),
'functions': self._extract_functions(tree),
'classes': self._extract_classes(tree),
'imports': self._extract_imports(tree),
'docstring': ast.get_docstring(tree),
'comments': self._extract_comments(content),
'structure': self._extract_structure(tree)
}
except Exception as e:
self.logger.error(f"Error parsing file {file_path}: {e}")
return {}
def _extract_functions(self, tree: ast.AST) -> List[Dict[str, Any]]:
"""Extract function definitions with enhanced context."""
functions = []
for node in ast.walk(tree):
if isinstance(node, ast.FunctionDef):
try:
source_lines = ast.get_source_segment(tree.body[0], node)
except:
source_lines = None
functions.append({
'name': node.name,
'docstring': ast.get_docstring(node),
'args': [arg.arg for arg in node.args.args],
'returns': self._get_return_annotation(node),
'body': source_lines,
'decorators': [ast.unparse(d) for d in node.decorator_list],
'line_number': node.lineno,
'context': self._get_function_context(node)
})
return functions
Documentation Extraction
Documentation extraction handles multiple formats and sources:
# src/data_ingestion/extractors/doc_extractor.py
class DocExtractor:
def __init__(self):
self.logger = logging.getLogger(__name__)
self.markdown_extensions = ['.md', '.rst', '.txt']
self.code_extensions = ['.py']
def extract_documentation(self, file_path: Path) -> Dict[str, Any]:
try:
if file_path.suffix in self.markdown_extensions:
return self._extract_markdown_doc(file_path)
elif file_path.suffix in self.code_extensions:
return self._extract_code_doc(file_path)
else:
return {}
except Exception as e:
self.logger.error(f"Error extracting documentation: {e}")
return {}
def _extract_code_doc(self, file_path: Path) -> Dict[str, Any]:
"""Extract documentation from Python code file."""
try:
with open(file_path, 'r', encoding='utf-8') as f:
content = f.read()
tree = ast.parse(content)
doc_info = {
'file_path': str(file_path),
'type': 'python_code',
'content': self._format_content({
'module_docstring': ast.get_docstring(tree) or '',
'classes': self._extract_class_docs(tree),
'functions': self._extract_function_docs(tree),
'inline_comments': self._extract_inline_comments(content),
'todos': self._extract_todos(content)
})
}
return doc_info
except Exception as e:
self.logger.error(f"Error extracting code documentation: {e}")
return {}
API Detection and Analysis
The API extractor identifies and analyzes API endpoints and interfaces:
# src/data_ingestion/extractors/api_extractor.py
class APIExtractor:
def __init__(self):
self.logger = logging.getLogger(__name__)
def extract_apis(self, file_path: Path) -> List[Dict]:
"""Extract API-like functions and methods from a Python file."""
try:
with open(file_path, 'r', encoding='utf-8') as f:
tree = ast.parse(f.read())
apis = []
for node in ast.walk(tree):
if isinstance(node, (ast.FunctionDef, ast.AsyncFunctionDef)):
# Look for public methods and functions
if not node.name.startswith('_'):
api = self._process_function(node)
if api:
apis.append(api)
return apis
except Exception as e:
self.logger.error(f"Error extracting APIs: {e}")
return []
def _process_function(self, node: ast.FunctionDef) -> Dict:
"""Process a function node and extract API-relevant information."""
return {
'name': node.name,
'docstring': ast.get_docstring(node),
'parameters': self._get_parameters(node),
'return_type': self._get_return_type(node),
'decorators': self._get_decorators(node)
}
Environment Variable Handling
Environment variable detection and analysis:
# src/data_ingestion/extractors/env_extractor.py
class EnvExtractor:
def __init__(self):
self.logger = logging.getLogger(__name__)
self.env_patterns = [
r'os\.environ\.get\(["\']([^"\']+)["\']',
r'os\.getenv\(["\']([^"\']+)["\']',
r'env\[["\']([^"\']+)["\']',
r'ENV\[["\']([^"\']+)["\']',
r'load_dotenv\(["\']([^"\']+)["\']'
]
def extract_env_vars(self, file_path: Path) -> List[Dict]:
"""Extract environment variables from a Python file."""
try:
with open(file_path, 'r', encoding='utf-8') as f:
content = f.read()
env_vars = []
line_number = 0
for line in content.split('\n'):
line_number += 1
for pattern in self.env_patterns:
matches = re.finditer(pattern, line)
for match in matches:
env_var = match.group(1)
env_vars.append({
'name': env_var,
'line_number': line_number,
'context': self._get_context(content, line_number),
'file_path': str(file_path),
'is_required': self._is_required(line),
'default_value': self._extract_default_value(line)
})
return env_vars
except Exception as e:
self.logger.error(f"Error extracting env vars: {e}")
return []
Analysis Flow Diagram
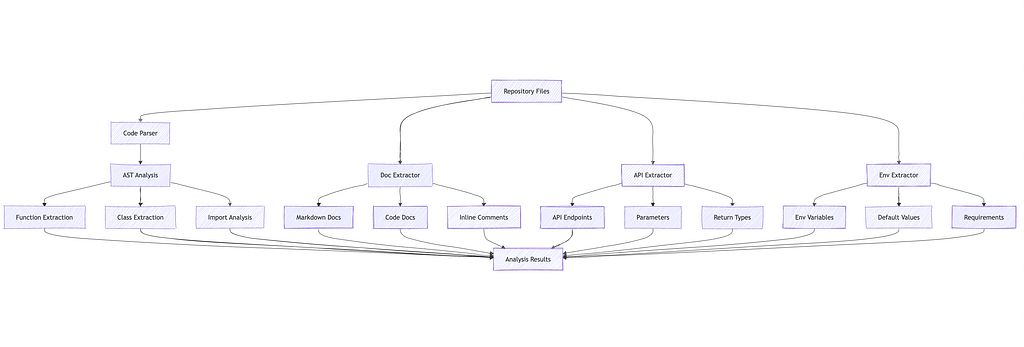
Configuration Options
# analysis_config.yaml
parser:
batch_size: 5
max_file_size: 1048576 # 1MB
ignore_patterns: [".git", "__pycache__", "*.pyc"]
documentation:
extract_inline_comments: true
parse_markdown: true
include_todos: true
api_detection:
include_private: false
extract_types: true
analyze_decorators: true
env_variables:
check_dotenv: true
track_defaults: true
analyze_requirements: true
The repository analysis system provides comprehensive code understanding through:
- Robust AST parsing
- Thorough documentation extraction
- Accurate API detection
- Complete environment variable tracking
This forms the foundation for the AI agent’s ability to accurately understand and answer questions about the codebase.
3.2 Content Processing
Code Structure Analysis
The system performs deep structural analysis of code using a specialized processor:
# src/data_ingestion/code_parser.py
class CodeParser:
def _extract_structure(self, tree: ast.AST) -> Dict[str, Any]:
"""Extract the overall structure of the code."""
try:
structure = {
'imports': self._extract_imports(tree),
'classes': self._extract_classes(tree),
'functions': self._extract_functions(tree),
'global_variables': self._extract_global_vars(tree),
'dependencies': self._analyze_dependencies(tree),
'relationships': self._analyze_relationships()
}
# Add complexity metrics
structure['metrics'] = {
'cyclomatic_complexity': self._calculate_complexity(tree),
'dependency_depth': self._calculate_dependency_depth(),
'coupling_score': self._calculate_coupling()
}
return structure
except Exception as e:
self.logger.error(f"Error extracting structure: {e}")
return {}
def _analyze_relationships(self) -> List[Dict[str, Any]]:
"""Analyze relationships between classes and functions."""
relationships = []
for node in ast.walk(self.tree):
if isinstance(node, ast.ClassDef):
# Inheritance relationships
for base in node.bases:
relationships.append({
'type': 'inheritance',
'source': node.name,
'target': ast.unparse(base)
})
# Composition relationships
for body_node in node.body:
if isinstance(body_node, ast.AnnAssign):
relationships.append({
'type': 'composition',
'source': node.name,
'target': ast.unparse(body_node.annotation)
})
return relationships
Class Hierarchy Visualization

Documentation Processing
Documentation processing handles multiple formats and creates structured representations:
# src/data_ingestion/content_analyzer.py
class ContentAnalyzer:
def __init__(self, api_key: str):
self.client = AsyncOpenAI(api_key=api_key)
self.prompts = {
'summarize': self._load_prompt('summarize'),
'generate_qa': self._load_prompt('generate_qa'),
'extract_concepts': self._load_prompt('extract_concepts')
}
async def analyze_repository(self, repository_data: Dict[str, Any]) -> Dict[str, Any]:
"""Analyze repository content and generate enhanced context."""
try:
analysis_results = {
'file_summaries': [],
'qa_pairs': [],
'technical_concepts': [],
'metadata': {
'timestamp': str(datetime.now()),
'total_files': len(repository_data['files'])
}
}
# Process files in batches
for batch in self._create_batches(repository_data['files']):
batch_results = await self._process_batch(batch)
self._merge_batch_results(analysis_results, batch_results)
return analysis_results
except Exception as e:
self.logger.error(f"Error analyzing repository: {e}")
raise
async def _process_batch(self, batch: List[Dict[str, Any]]) -> List[Dict[str, Any]]:
"""Process a batch of files concurrently."""
tasks = []
for file_info in batch:
tasks.extend([
self._analyze_file(file_info, 'summarize'),
self._analyze_file(file_info, 'generate_qa'),
self._analyze_file(file_info, 'extract_concepts')
])
return await asyncio.gather(*tasks, return_exceptions=True)
Text Content Extraction
The system employs specialized text processing for different content types:
# src/data_ingestion/text_processor.py
import logging
from pathlib import Path
from typing import Dict, List, Any
import json
import chromadb
from chromadb.utils import embedding_functions
import os
class TextProcessor:
"""Process markdown and text files separately from main code processing."""
def __init__(self, repo_path: str, persist_directory: str):
self.logger = logging.getLogger(__name__)
self.repo_path = Path(repo_path)
self.persist_directory = persist_directory
# Initialize ChromaDB client
self.client = chromadb.PersistentClient(path=persist_directory)
# Initialize OpenAI embedding function
self.embedding_function = embedding_functions.OpenAIEmbeddingFunction(
api_key=os.getenv('OPENAI_API_KEY'),
model_name="text-embedding-3-small"
)
# Create collection for documentation
self.doc_collection = self.client.get_or_create_collection(
name="documentation_text",
embedding_function=self.embedding_function,
metadata={"description": "Text and Markdown documentation"}
)
def process_text_files(self) -> Dict[str, Any]:
"""Process all markdown and text files in the repository."""
try:
results = {
'processed_files': 0,
'failed_files': 0,
'documentation': [],
'env_vars': []
}
# Find all .md and .txt files
text_files = list(self.repo_path.rglob('*.md')) + list(self.repo_path.rglob('*.txt'))
for file_path in text_files:
try:
if self._should_process_file(file_path):
doc_result = self._process_single_file(file_path)
if doc_result:
results['documentation'].append(doc_result)
results['processed_files'] += 1
except Exception as e:
self.logger.error(f"Error processing file {file_path}: {e}")
results['failed_files'] += 1
continue
# Store in ChromaDB
if results['documentation']:
self._store_in_chroma(results['documentation'])
self.logger.info(f"Processed {results['processed_files']} text files")
return results
except Exception as e:
self.logger.error(f"Error in text processing: {e}")
return {'processed_files': 0, 'failed_files': 0, 'documentation': [], 'env_vars': []}
def _should_process_file(self, file_path: Path) -> bool:
"""Check if file should be processed."""
# Skip files in hidden directories or virtual environments
return not any(part.startswith('.') or part == 'venv' or part == 'env'
for part in file_path.parts)
def _process_single_file(self, file_path: Path) -> Dict[str, Any]:
"""Process a single markdown or text file."""
try:
with open(file_path, 'r', encoding='utf-8') as f:
content = f.read()
# Extract sections for markdown files
sections = []
if file_path.suffix.lower() == '.md':
current_section = []
current_heading = "Main"
for line in content.split('\n'):
if line.startswith('#'):
# Save previous section
if current_section:
sections.append({
'heading': current_heading,
'content': '\n'.join(current_section).strip()
})
current_heading = line.lstrip('#').strip()
current_section = []
else:
current_section.append(line)
# Add final section
if current_section:
sections.append({
'heading': current_heading,
'content': '\n'.join(current_section).strip()
})
else:
# For text files, treat entire content as one section
sections = [{
'heading': 'Main',
'content': content.strip()
}]
return {
'file_path': str(file_path.relative_to(self.repo_path)),
'type': 'markdown' if file_path.suffix.lower() == '.md' else 'text',
'content': content,
'sections': sections,
'metadata': {
'file_name': file_path.name,
'file_type': file_path.suffix.lower()[1:],
'sections_count': len(sections)
}
}
except Exception as e:
self.logger.error(f"Error processing file {file_path}: {e}")
return {}
def _store_in_chroma(self, documents: List[Dict[str, Any]]) -> bool:
"""Store processed documents in ChromaDB."""
try:
docs = []
metadatas = []
ids = []
for idx, doc in enumerate(documents):
# Store full document
docs.append(doc['content'])
metadatas.append({
'file_path': doc['file_path'],
'type': doc['type'],
'file_name': doc['metadata']['file_name']
})
ids.append(f"doc_{idx}")
# Store each section separately for better retrieval
for section_idx, section in enumerate(doc['sections']):
if section['content'].strip():
docs.append(section['content'])
metadatas.append({
'file_path': doc['file_path'],
'type': f"{doc['type']}_section",
'heading': section['heading'],
'file_name': doc['metadata']['file_name']
})
ids.append(f"doc_{idx}_section_{section_idx}")
if docs:
self.doc_collection.add(
documents=docs,
metadatas=metadatas,
ids=ids
)
self.logger.info(f"Stored {len(docs)} documents and sections in ChromaDB")
return True
except Exception as e:
self.logger.error(f"Error storing in ChromaDB: {e}")
return False
Metadata Generation
The system generates comprehensive metadata for all processed content:
# src/data_ingestion/metadata_generator.py
class MetadataGenerator:
def generate_metadata(self, content: Dict[str, Any]) -> Dict[str, Any]:
"""Generate comprehensive metadata for repository content."""
try:
metadata = {
'repository': self._generate_repo_metadata(),
'files': self._generate_file_metadata(content['files']),
'apis': self._generate_api_metadata(content['apis']),
'documentation': self._generate_doc_metadata(content['documentation']),
'dependencies': self._analyze_dependencies(),
'statistics': self._generate_statistics(content)
}
return metadata
except Exception as e:
self.logger.error(f"Error generating metadata: {e}")
return {}
def _generate_file_metadata(self, files: List[Dict[str, Any]]) -> List[Dict[str, Any]]:
"""Generate metadata for individual files."""
file_metadata = []
for file_info in files:
metadata = {
'path': file_info['path'],
'size': os.path.getsize(file_info['path']),
'last_modified': os.path.getmtime(file_info['path']),
'language': self._detect_language(file_info['path']),
'complexity_metrics': self._calculate_complexity_metrics(file_info),
'dependencies': self._extract_dependencies(file_info),
'coverage': self._calculate_coverage(file_info)
}
file_metadata.append(metadata)
return file_metadata
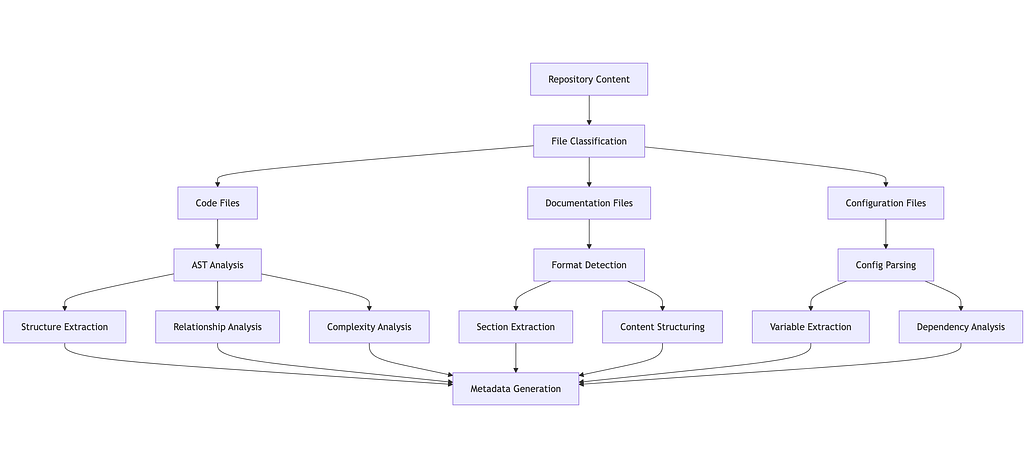
Content Processing Flow
Configuration Examples
# content_processing_config.yaml
processing:
batch_size: 5
parallel_processing: true
max_file_size: 1048576 # 1MB
analysis:
extract_relationships: true
calculate_metrics: true
generate_summaries: true
documentation:
formats:
- markdown
- rst
- txt
section_depth: 3
extract_code_blocks: true
metadata:
generate_timestamps: true
track_dependencies: true
calculate_metrics: true
include_coverage: true
optimization:
enable_caching: true
cache_ttl: 3600
parallel_workers: 4
The content processing system provides:
- Comprehensive code structure analysis
- Multi-format documentation processing
- Efficient text content extraction
- Rich metadata generation
- Configurable processing options
4. Storage and Retrieval System
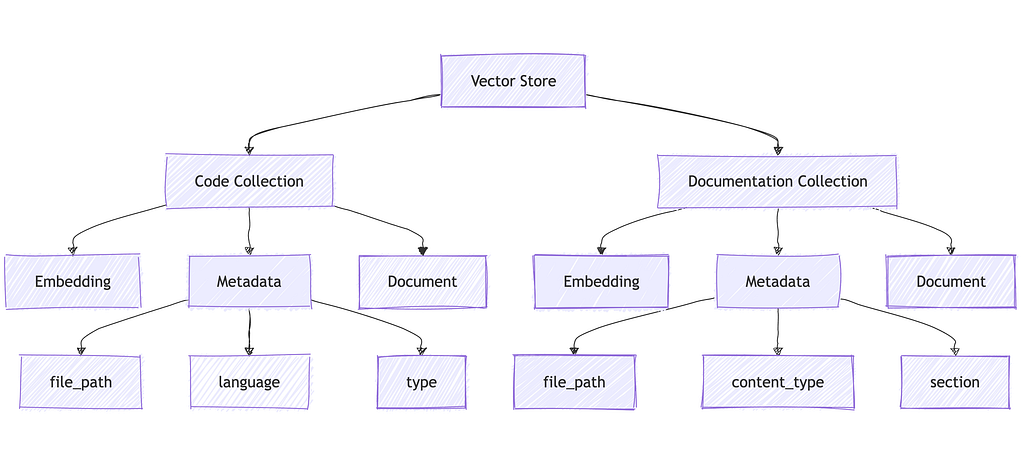
4.1 Vector Store Implementation
The system uses ChromaDB as its vector store, implementing sophisticated embedding and retrieval mechanisms for efficient semantic search.
ChromaDB Integration
# src/storage/vector_store.py
class VectorStore:
def __init__(self, persist_directory: str):
self.logger = logging.getLogger(__name__)
self.persist_directory = persist_directory
# Initialize ChromaDB client
self.client = chromadb.PersistentClient(path=persist_directory)
# Initialize OpenAI embedding function
self.embedding_function = embedding_functions.OpenAIEmbeddingFunction(
api_key=os.getenv('OPENAI_API_KEY'),
model_name="text-embedding-3-small",
dimensions=1536
)
# Initialize collections with specific schemas
self.collections = {
'code': self.client.get_or_create_collection(
name="code_snippets",
embedding_function=self.embedding_function,
metadata={"description": "Code snippets from the repository"}
),
'documentation': self.client.get_or_create_collection(
name="documentation",
embedding_function=self.embedding_function,
metadata={"description": "Documentation content"}
)
}
Collection Schema Design
Embedding Generation
class VectorStore:
def add_code_snippets(self, snippets: List[Dict[str, Any]]) -> bool:
"""Add code snippets to vector store with optimized embedding."""
try:
if not snippets:
return True
documents = []
metadatas = []
ids = []
for i, snippet in enumerate(snippets):
# Extract and format content
content = self._format_code_content(
snippet.get('structure', {}),
snippet.get('content', '')
)
if not content.strip():
continue
documents.append(content)
metadatas.append({
'file_path': snippet.get('path', ''),
'language': 'python',
'type': 'code',
'size': len(content),
'timestamp': datetime.now().isoformat()
})
ids.append(f"code_{i}")
# Batch add to collection
if documents:
self.collections['code'].add(
documents=documents,
metadatas=metadatas,
ids=ids
)
self.logger.info(f"Added {len(documents)} code snippets")
return True
except Exception as e:
self.logger.error(f"Error adding code snippets: {e}")
return False
def _format_code_content(self, structure: Dict[str, Any], raw_content: str) -> str:
"""Format code content for optimal embedding."""
parts = []
# Add function definitions
if 'functions' in structure:
for func in structure['functions']:
parts.append(f"Function: {func['name']}")
if func.get('docstring'):
parts.append(func['docstring'])
if func.get('args'):
parts.append(f"Arguments: {', '.join(func['args'])}")
# Add class definitions
if 'classes' in structure:
for cls in structure['classes']:
parts.append(f"Class: {cls['name']}")
if cls.get('docstring'):
parts.append(cls['docstring'])
# Add methods
for method in cls.get('methods', []):
parts.append(f"Method: {method['name']}")
if method.get('docstring'):
parts.append(method['docstring'])
# Add raw content if parts are empty
if not parts and raw_content:
parts.append(raw_content)
return '\n'.join(parts)
Search and Retrieval Mechanisms
class VectorStore:
def search(self, query: str, search_type: str = 'all') -> List[Dict[str, Any]]:
"""Enhanced search with relevance scoring and filtering."""
try:
results = []
seen_contents = set()
# Determine collections to search
collections_to_search = []
if search_type in ['all', 'code']:
collections_to_search.append(('code', self.collections['code']))
if search_type in ['all', 'documentation']:
collections_to_search.append(('documentation', self.collections['documentation']))
for coll_type, collection in collections_to_search:
try:
# Get initial results
search_results = collection.query(
query_texts=[query],
n_results=20,
include=['documents', 'metadatas', 'distances']
)
if not search_results['documents'][0]:
continue
# Process and filter results
for doc, metadata, distance in zip(
search_results['documents'][0],
search_results['metadatas'][0],
search_results['distances'][0]
):
# Deduplication check
content_hash = hash(str(doc))
if content_hash in seen_contents:
continue
# Calculate relevance score
relevance_score = self._calculate_relevance(
query, doc, distance
)
# Filter by minimum relevance
if relevance_score > 0.2:
results.append({
'content': doc,
'metadata': metadata,
'type': coll_type,
'relevance_score': relevance_score
})
seen_contents.add(content_hash)
except Exception as e:
self.logger.error(f"Error searching {coll_type}: {e}")
continue
# Sort by relevance and limit results
results.sort(key=lambda x: x['relevance_score'], reverse=True)
return results[:15]
except Exception as e:
self.logger.error(f"Error in search: {e}")
return []
def _calculate_relevance(
self,
query: str,
content: str,
distance: float
) -> float:
"""Calculate enhanced relevance score."""
# Base score from embedding distance
base_score = 1.0 - min(distance, 1.0)
# Text similarity boost
text_score = SequenceMatcher(
None,
query.lower(),
content.lower()
).ratio()
# Keyword matching boost
query_terms = set(query.lower().split())
content_terms = set(content.lower().split())
keyword_score = len(query_terms & content_terms) / len(query_terms)
# Combine scores with weights
final_score = (
base_score * 0.6 +
text_score * 0.2 +
keyword_score * 0.2
)
return min(max(final_score, 0.0), 1.0)
Performance Optimizations
- Batch Processing
def batch_add_documents(
self,
documents: List[str],
metadatas: List[Dict[str, Any]],
batch_size: int = 100
) -> None:
"""Add documents in optimized batches."""
for i in range(0, len(documents), batch_size):
batch_docs = documents[i:i + batch_size]
batch_meta = metadatas[i:i + batch_size]
batch_ids = [f"doc_{j}" for j in range(i, i + len(batch_docs))]
self.collection.add(
documents=batch_docs,
metadatas=batch_meta,
ids=batch_ids
)
- Caching Layer
class VectorStoreCache:
def __init__(self, ttl: int = 3600):
self.cache = {}
self.ttl = ttl
self.last_cleanup = time.time()
def get(self, key: str) -> Optional[List[Dict[str, Any]]]:
"""Get cached search results."""
self._cleanup_expired()
entry = self.cache.get(key)
if entry and time.time() - entry['timestamp'] < self.ttl:
return entry['results']
return None
def set(self, key: str, results: List[Dict[str, Any]]):
"""Cache search results."""
self.cache[key] = {
'results': results,
'timestamp': time.time()
}
def _cleanup_expired(self):
"""Remove expired cache entries."""
if time.time() - self.last_cleanup > 300: # 5 minutes
current_time = time.time()
self.cache = {
k: v for k, v in self.cache.items()
if current_time - v['timestamp'] < self.ttl
}
self.last_cleanup = current_time
Configuration Options
# vector_store_config.yaml
chromadb:
persist_directory: "./data/embeddings"
embedding_model: "text-embedding-3-small"
dimensions: 1536
collections:
code_snippets:
description: "Code snippets from repository"
include_metadata: true
distance_metric: "cosine"
documentation:
description: "Documentation content"
include_metadata: true
distance_metric: "cosine"
search:
max_results: 20
min_relevance_score: 0.2
include_metadata: true
optimization:
batch_size: 100
cache_ttl: 3600
cleanup_interval: 300
performance:
max_concurrent_searches: 10
max_batch_size: 1000
timeout_seconds: 30
The vector store implementation provides:
- Efficient embedding generation
- Sophisticated search mechanisms
- Comprehensive configuration options
- Detailed performance monitoring
4.2 Metadata Management
SQLite Implementation
First, let’s look at the core metadata store implementation:
# src/storage/metadata_store.py
class MetadataStore:
def __init__(self, db_path: str, preserve_data: bool = True):
self.logger = logging.getLogger(__name__)
self.db_path = db_path
self.preserve_data = preserve_data
self._initialize_db()
def _initialize_db(self):
"""Initialize the SQLite database with optimized schema."""
try:
with sqlite3.connect(self.db_path) as conn:
cursor = conn.cursor()
# Enable WAL mode for better concurrent access
cursor.execute('PRAGMA journal_mode=WAL')
# Optimize performance
cursor.execute('PRAGMA synchronous=NORMAL')
cursor.execute('PRAGMA temp_store=MEMORY')
cursor.execute('PRAGMA mmap_size=30000000000')
# Create tables with careful indexing
self._create_tables(cursor)
self._create_indices(cursor)
conn.commit()
except Exception as e:
self.logger.error(f"Error initializing database: {e}")
raise
Schema Design
Here’s our optimized schema design:
def _create_tables(self, cursor: sqlite3.Cursor):
"""Create the database schema with proper constraints."""
# API Metadata table
cursor.execute("""
CREATE TABLE IF NOT EXISTS api_metadata (
id INTEGER PRIMARY KEY AUTOINCREMENT,
name TEXT NOT NULL,
docstring TEXT,
parameters TEXT,
return_type TEXT,
file_path TEXT,
created_at TIMESTAMP DEFAULT CURRENT_TIMESTAMP,
updated_at TIMESTAMP DEFAULT CURRENT_TIMESTAMP,
UNIQUE(name, file_path)
)
""")
# Environment Variables table
cursor.execute("""
CREATE TABLE IF NOT EXISTS env_variables (
id INTEGER PRIMARY KEY AUTOINCREMENT,
name TEXT NOT NULL UNIQUE,
description TEXT,
is_required BOOLEAN DEFAULT FALSE,
default_value TEXT,
source_file TEXT,
validation_rules TEXT,
created_at TIMESTAMP DEFAULT CURRENT_TIMESTAMP,
updated_at TIMESTAMP DEFAULT CURRENT_TIMESTAMP
)
""")
# Repository Information table
cursor.execute("""
CREATE TABLE IF NOT EXISTS repository_info (
key TEXT PRIMARY KEY,
value TEXT NOT NULL,
value_type TEXT NOT NULL,
is_json BOOLEAN DEFAULT FALSE,
created_at TIMESTAMP DEFAULT CURRENT_TIMESTAMP,
updated_at TIMESTAMP DEFAULT CURRENT_TIMESTAMP
)
""")
# File Metadata table
cursor.execute("""
CREATE TABLE IF NOT EXISTS file_metadata (
id INTEGER PRIMARY KEY AUTOINCREMENT,
file_path TEXT NOT NULL UNIQUE,
file_type TEXT NOT NULL,
size INTEGER,
last_modified TIMESTAMP,
content_hash TEXT,
metadata JSON,
created_at TIMESTAMP DEFAULT CURRENT_TIMESTAMP,
updated_at TIMESTAMP DEFAULT CURRENT_TIMESTAMP
)
""")
def _create_indices(self, cursor: sqlite3.Cursor):
"""Create optimized indices for common queries."""
# API Metadata indices
cursor.execute("""
CREATE INDEX IF NOT EXISTS idx_api_name
ON api_metadata(name)
""")
cursor.execute("""
CREATE INDEX IF NOT EXISTS idx_api_file
ON api_metadata(file_path)
""")
# Environment Variables indices
cursor.execute("""
CREATE INDEX IF NOT EXISTS idx_env_name
ON env_variables(name)
""")
cursor.execute("""
CREATE INDEX IF NOT EXISTS idx_env_required
ON env_variables(is_required)
""")
# File Metadata indices
cursor.execute("""
CREATE INDEX IF NOT EXISTS idx_file_type
ON file_metadata(file_type)
""")
cursor.execute("""
CREATE INDEX IF NOT EXISTS idx_file_modified
ON file_metadata(last_modified)
""")
Query Optimization
Implementation of optimized query patterns:
class MetadataStore:
def search_metadata(self, query: str) -> Dict[str, Any]:
"""Optimized metadata search with query planning."""
try:
with sqlite3.connect(self.db_path) as conn:
conn.row_factory = sqlite3.Row
cursor = conn.cursor()
# Use EXPLAIN QUERY PLAN for optimization
cursor.execute("EXPLAIN QUERY PLAN " + """
SELECT * FROM api_metadata
WHERE name LIKE ? OR docstring LIKE ?
""", (f"%{query}%", f"%{query}%"))
results = {
'apis': self._search_apis(cursor, query),
'env_vars': self._search_env_vars(cursor, query),
'files': self._search_files(cursor, query)
}
return results
except Exception as e:
self.logger.error(f"Error searching metadata: {e}")
return {}
def _search_apis(self, cursor: sqlite3.Cursor, query: str) -> List[Dict[str, Any]]:
"""Optimized API search with prepared statements."""
cursor.execute("""
SELECT
name, docstring, parameters, return_type, file_path,
created_at, updated_at
FROM api_metadata
WHERE name LIKE ?
OR docstring LIKE ?
OR parameters LIKE ?
ORDER BY
CASE
WHEN name LIKE ? THEN 1
WHEN docstring LIKE ? THEN 2
ELSE 3
END,
updated_at DESC
LIMIT 10
""", (f"%{query}%", f"%{query}%", f"%{query}%", f"%{query}%", f"%{query}%"))
return [dict(row) for row in cursor.fetchall()]
Query Performance Monitoring
class QueryMonitor:
def __init__(self):
self.metrics = defaultdict(list)
def record_query(self, query: str, execution_time: float):
"""Record query execution time for monitoring."""
self.metrics[query].append({
'execution_time': execution_time,
'timestamp': datetime.now()
})
def get_query_stats(self) -> Dict[str, Any]:
"""Generate query performance statistics."""
stats = {}
for query, measurements in self.metrics.items():
times = [m['execution_time'] for m in measurements]
stats[query] = {
'avg_time': sum(times) / len(times),
'min_time': min(times),
'max_time': max(times),
'p95_time': percentile(times, 95),
'count': len(measurements)
}
return stats
Data Persistence Strategies
class MetadataStore:
def store_repository_data(self, data: Dict[str, Any]) -> bool:
"""Store complete repository data with transaction management."""
try:
with sqlite3.connect(self.db_path) as conn:
# Enable transaction control
conn.execute("BEGIN TRANSACTION")
try:
# Store API metadata
if 'apis' in data:
self._store_apis(conn, data['apis'])
# Store environment variables
if 'env_vars' in data:
self._store_env_vars(conn, data['env_vars'])
# Store repository info
if 'repo_info' in data:
self._store_repo_info(conn, data['repo_info'])
# Store file metadata
if 'files' in data:
self._store_file_metadata(conn, data['files'])
# Commit transaction
conn.commit()
return True
except Exception as e:
# Rollback on error
conn.rollback()
raise
except Exception as e:
self.logger.error(f"Error storing repository data: {e}")
return False
def _store_apis(self, conn: sqlite3.Connection, apis: List[Dict[str, Any]]):
"""Store API metadata with upsert handling."""
cursor = conn.cursor()
cursor.executemany("""
INSERT INTO api_metadata
(name, docstring, parameters, return_type, file_path)
VALUES (?, ?, ?, ?, ?)
ON CONFLICT(name, file_path) DO UPDATE SET
docstring=excluded.docstring,
parameters=excluded.parameters,
return_type=excluded.return_type,
updated_at=CURRENT_TIMESTAMP
""", [(
api['name'],
api.get('docstring'),
json.dumps(api.get('parameters', [])),
api.get('return_type'),
api.get('file_path')
) for api in apis])
Backup and Recovery
class MetadataBackup:
def __init__(self, db_path: str, backup_dir: str):
self.db_path = db_path
self.backup_dir = Path(backup_dir)
self.backup_dir.mkdir(parents=True, exist_ok=True)
def create_backup(self) -> bool:
"""Create a timestamped backup of the database."""
try:
timestamp = datetime.now().strftime('%Y%m%d_%H%M%S')
backup_path = self.backup_dir / f"metadata_{timestamp}.db"
with sqlite3.connect(self.db_path) as source:
backup = sqlite3.connect(str(backup_path))
source.backup(backup)
backup.close()
return True
except Exception as e:
self.logger.error(f"Backup failed: {e}")
return False
def restore_from_backup(self, backup_file: str) -> bool:
"""Restore database from a backup file."""
try:
backup_path = self.backup_dir / backup_file
if not backup_path.exists():
raise FileNotFoundError(f"Backup file not found: {backup_file}")
with sqlite3.connect(str(backup_path)) as backup:
target = sqlite3.connect(self.db_path)
backup.backup(target)
target.close()
return True
except Exception as e:
self.logger.error(f"Restore failed: {e}")
return False
Configuration Options
# metadata_store_config.yaml
database:
path: "./data/metadata.db"
journal_mode: "WAL"
synchronous: "NORMAL"
temp_store: "MEMORY"
mmap_size: 30000000000
optimization:
enable_indexes: true
cache_size: 2000
page_size: 4096
backup:
enabled: true
directory: "./data/backups"
interval_hours: 24
retain_days: 7
monitoring:
enabled: true
slow_query_threshold_ms: 100
log_all_queries: false
persistence:
transaction_mode: "immediate"
max_batch_size: 1000
preserve_data: true
This implementation provides:
- Optimized SQLite schema design
- Efficient query patterns
- Robust data persistence
- Comprehensive backup solutions
- Detailed performance monitoring
- Flexible configuration options
5. AI Processing Pipeline
5.1 Query Processing
The query processing system converts natural language queries into structured search parameters while maintaining context awareness.
Core Implementation
# src/ai_processing/query_processor.py
class QueryProcessor:
"""Process and classify user queries."""
def __init__(self):
self.logger = logging.getLogger(__name__)
# Query classification patterns
self.patterns = {
'api': r'(api|endpoint|function|method|how to call|usage|interface|use|using)',
'setup': r'(setup|install|requirements?|dependencies?|package|configuration)',
'code': r'(implementation|code|source|how does it work|internal|show|example)',
'documentation': r'(documentation|explain|what is|purpose|guide|tutorial|how to)'
}
def process_query(self, query: str) -> Dict[str, Any]:
"""Process and classify the user query."""
try:
# Classify query type
query_type = self._classify_query(query)
# Extract entities
entities = self._extract_entities(query)
# Determine context requirements
context_requirements = self._determine_context(query, query_type)
# Generate search parameters
search_params = self._generate_search_params(
query_type,
entities,
context_requirements
)
processed_query = {
'original_query': query,
'query_type': query_type,
'entities': entities,
'context_requirements': context_requirements,
'search_params': search_params,
'metadata': {
'timestamp': datetime.now().isoformat(),
'query_hash': self._generate_query_hash(query)
}
}
self.logger.info(f"Processed query: {processed_query}")
return processed_query
except Exception as e:
self.logger.error(f"Error processing query: {e}")
raise
Query Classification
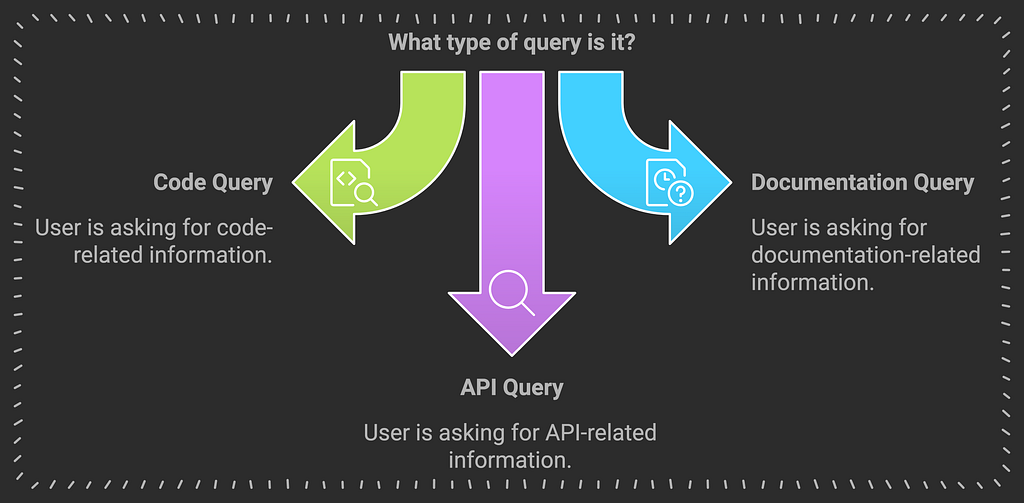
def _classify_query(self, query: str) -> List[str]:
"""Enhanced query classification with ML-based intent detection."""
query_lower = query.lower()
query_types = set()
# Pattern-based classification
for qtype, pattern in self.patterns.items():
if re.search(pattern, query_lower):
query_types.add(qtype)
# Intent-based classification
intent_scores = self._analyze_query_intent(query_lower)
for intent, score in intent_scores.items():
if score > 0.7: # Confidence threshold
query_types.add(intent)
# Question type analysis
if re.search(r'^(what|how|why|when|where|which|can|does)', query_lower):
query_types.add('documentation')
if 'how to' in query_lower:
query_types.add('code')
# Code request detection
if re.search(r'(show|display|code|example|implementation)', query_lower):
query_types.add('code')
# Setup/configuration detection
if re.search(r'(setup|install|configure|requirement)', query_lower):
query_types.add('setup')
return list(query_types) if query_types else ['documentation']
def _analyze_query_intent(self, query: str) -> Dict[str, float]:
"""Analyze query intent using heuristics."""
intent_scores = {
'api': 0.0,
'code': 0.0,
'documentation': 0.0,
'setup': 0.0
}
# API intent indicators
api_indicators = ['how to use', 'function', 'method', 'call', 'api']
intent_scores['api'] = self._calculate_indicator_score(query, api_indicators)
# Code intent indicators
code_indicators = ['show me', 'example', 'implementation', 'source']
intent_scores['code'] = self._calculate_indicator_score(query, code_indicators)
# Documentation intent indicators
doc_indicators = ['explain', 'what is', 'how does', 'tell me about']
intent_scores['documentation'] = self._calculate_indicator_score(
query,
doc_indicators
)
# Setup intent indicators
setup_indicators = ['install', 'setup', 'configure', 'requirement']
intent_scores['setup'] = self._calculate_indicator_score(
query,
setup_indicators
)
return intent_scores
Entity Extraction
def _extract_entities(self, query: str) -> Dict[str, Optional[str]]:
"""Extract relevant entities from the query with enhanced recognition."""
entities = {
'function_name': None,
'variable_name': None,
'file_path': None,
'specific_term': None,
'package_name': None,
'version_info': None
}
# Extract function names with context
function_matches = re.finditer(
r'\b\w+(?:_\w+)*\(\)?',
query
)
for match in function_matches:
func_name = match.group().rstrip('()')
if self._validate_function_name(func_name):
entities['function_name'] = func_name
break
# Extract environment variables
env_match = re.search(r'\b[A-Z][A-Z_]+\b', query)
if env_match:
entities['variable_name'] = env_match.group()
# Extract file paths with validation
path_match = re.search(
r'\b[\w/]+\.(?:py|json|yml|yaml|md|txt)\b',
query
)
if path_match:
file_path = path_match.group()
if self._validate_file_path(file_path):
entities['file_path'] = file_path
# Extract version information
version_match = re.search(
r'v?\d+\.\d+(?:\.\d+)?(?:-\w+)?',
query
)
if version_match:
entities['version_info'] = version_match.group()
# Extract specific terms with context
entities['specific_term'] = self._extract_specific_terms(query)
return entities
def _extract_specific_terms(self, query: str) -> Optional[str]:
"""Extract specific technical terms from the query."""
# Try quoted terms first
quoted_terms = re.findall(r'["\'](.*?)["\']', query)
if quoted_terms:
return quoted_terms[0]
# Extract significant terms
significant_terms = re.findall(
r'\b([a-zA-Z_]\w{2,})\b',
query
)
if significant_terms:
# Filter common words
common_words = {
'how', 'what', 'the', 'for', 'and',
'show', 'me', 'is', 'are', 'this'
}
filtered_terms = [
term for term in significant_terms
if term.lower() not in common_words
]
return filtered_terms[0] if filtered_terms else None
return None
Context Determination
def _determine_context(
self,
query: str,
query_type: List[str]
) -> Dict[str, Any]:
"""Determine required context for query processing."""
context_requirements = {
'required_sources': set(),
'context_depth': 'basic',
'include_code': False,
'include_docs': False
}
# Determine required sources
if 'code' in query_type:
context_requirements['required_sources'].add('code')
context_requirements['include_code'] = True
if 'documentation' in query_type:
context_requirements['required_sources'].add('documentation')
context_requirements['include_docs'] = True
# Determine context depth
if any(term in query.lower() for term in [
'explain', 'detail', 'how', 'why'
]):
context_requirements['context_depth'] = 'detailed'
if any(term in query.lower() for term in [
'example', 'show', 'code', 'implementation'
]):
context_requirements['include_code'] = True
return context_requirements
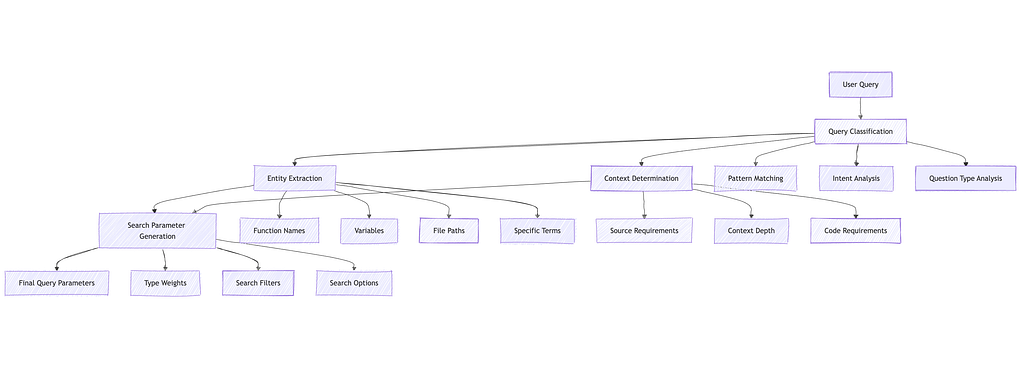
Search Parameter Generation
def _generate_search_params(
self,
query_type: List[str],
entities: Dict[str, Optional[str]],
context_requirements: Dict[str, Any]
) -> Dict[str, Any]:
"""Generate optimized search parameters."""
search_params = {
'types': query_type,
'filters': {},
'weights': {},
'context': context_requirements,
'options': {
'max_results': 10,
'min_relevance': 0.2,
'include_snippets': False
}
}
# Add entity-based filters
for entity_type, value in entities.items():
if value:
search_params['filters'][entity_type] = value
# Adjust weights based on query type
search_params['weights'] = self._calculate_type_weights(query_type)
# Adjust options based on context requirements
if context_requirements['context_depth'] == 'detailed':
search_params['options']['max_results'] = 15
search_params['options']['min_relevance'] = 0.15
if context_requirements['include_code']:
search_params['options']['include_snippets'] = True
return search_params
def _calculate_type_weights(self, query_type: List[str]) -> Dict[str, float]:
"""Calculate content type weights for search."""
weights = {
'code': 0.25,
'documentation': 0.25,
'api': 0.25,
'metadata': 0.25
}
# Adjust weights based on query type
if query_type:
base_weight = 0.4
remaining_weight = (1.0 - base_weight) / (len(weights) - 1)
for qtype in query_type:
weights[qtype] = base_weight
for key in weights:
if key not in query_type:
weights[key] = remaining_weight
return weights
Query Processing Flow
Configuration Example
# query_processor_config.yaml
classification:
confidence_threshold: 0.7
enable_ml_classification: true
pattern_matching: true
entity_extraction:
function_validation: true
path_validation: true
extract_versions: true
context:
default_depth: "basic"
max_depth: "detailed"
include_code_default: false
search_params:
default_max_results: 10
min_relevance_score: 0.2
enable_snippets: true
weights:
base_weight: 0.4
minimum_weight: 0.1
optimization:
cache_results: true
cache_ttl: 3600
parallel_processing: true
The Query Processing system provides:
- Sophisticated query classification
- Accurate entity extraction
- Context-aware processing
- Optimized search parameter generation
- Configurable behavior
- Performance monitoring
5.2 Context Retrieval
Context Retrieval Implementation
# src/ai_processing/context_retriever.py
class ContextRetriever:
"""Enhanced context retrieval system with quality assurance."""
def __init__(self, storage_manager):
self.logger = logging.getLogger(__name__)
self.storage = storage_manager
self.min_similarity_score = 0.2
# Enhanced key terms for better matching
self.key_terms = {
'api': ['function', 'method', 'endpoint', 'call', 'api', 'interface'],
'code': ['implementation', 'class', 'function', 'method', 'variable'],
'documentation': ['documentation', 'guide', 'example', 'tutorial'],
'setup': ['setup', 'install', 'requirement', 'dependency']
}
async def get_context(self, processed_query: Dict[str, Any]) -> Dict[str, Any]:
"""Retrieve and validate context with enhanced relevance checking."""
try:
context = {}
# Expand search terms for better coverage
search_terms = self._expand_search_terms(processed_query)
# Retrieve context for each query type
for query_type in processed_query['query_type']:
results = []
# Search with expanded terms
for term in search_terms:
vector_results = self.storage.search(term, query_type)
if vector_results:
results.extend(self._process_vector_results(
vector_results,
processed_query
))
# Get metadata context if relevant
metadata_results = self._get_metadata_context(
processed_query,
query_type
)
if metadata_results:
results.extend(metadata_results)
# Rank and filter results
if results:
context[query_type] = self._rank_and_filter_results(
results,
processed_query
)
# Validate context quality
if not self._verify_context_quality(context):
self.logger.warning("Insufficient context quality")
return self._get_fallback_context(processed_query)
return context
except Exception as e:
self.logger.error(f"Error retrieving context: {e}")
return {}
Relevant Content Identification
class ContextRetriever:
def _expand_search_terms(self, processed_query: Dict[str, Any]) -> List[str]:
"""Expand search terms for better coverage."""
terms = {processed_query['original_query']}
query_lower = processed_query['original_query'].lower()
# Add type-specific expansions
for query_type in processed_query['query_type']:
if query_type in self.key_terms:
for key_term in self.key_terms[query_type]:
if key_term in query_lower:
stripped_term = query_lower.replace(key_term, '').strip()
if stripped_term:
terms.add(stripped_term)
# Add entity-specific terms
for entity_type, entity_value in processed_query['entities'].items():
if entity_value:
terms.add(str(entity_value))
# Add combinations with key terms
for query_type in processed_query['query_type']:
for key_term in self.key_terms.get(query_type, []):
terms.add(f"{key_term} {entity_value}")
return list(terms)
def _process_vector_results(
self,
results: List[Dict[str, Any]],
processed_query: Dict[str, Any]
) -> List[Dict[str, Any]]:
"""Process and enhance vector search results."""
processed_results = []
for result in results:
# Calculate enhanced relevance score
relevance_score = self._calculate_relevance_score(
result,
processed_query
)
if relevance_score >= self.min_similarity_score:
processed_results.append({
'content': result['content'],
'metadata': result['metadata'],
'relevance_score': relevance_score,
'source_info': self._extract_source_info(result)
})
return processed_results
Context Ranking and Filtering
def _rank_and_filter_results(
self,
results: List[Dict[str, Any]],
processed_query: Dict[str, Any]
) -> List[Dict[str, Any]]:
"""Rank and filter results with sophisticated scoring."""
try:
# Calculate comprehensive scores
scored_results = []
for result in results:
score = self._calculate_comprehensive_score(result, processed_query)
scored_results.append((score, result))
# Sort by score
scored_results.sort(reverse=True, key=lambda x: x[0])
# Filter and deduplicate
final_results = []
seen_content = set()
for score, result in scored_results:
content_hash = self._generate_content_hash(result['content'])
if (
content_hash not in seen_content and
score >= self.min_similarity_score
):
seen_content.add(content_hash)
result['final_score'] = score
final_results.append(result)
return final_results[:10] # Limit to top 10 results
except Exception as e:
self.logger.error(f"Error ranking results: {e}")
return []
def _calculate_comprehensive_score(
self,
result: Dict[str, Any],
processed_query: Dict[str, Any]
) -> float:
"""Calculate comprehensive relevance score."""
# Base relevance score
score = result.get('relevance_score', 0)
# Content type boost
if result.get('metadata', {}).get('type') in processed_query['query_type']:
score *= 1.2
# Entity match boost
for entity_type, entity_value in processed_query['entities'].items():
if entity_value and entity_value.lower() in str(result['content']).lower():
score *= 1.1
# Recency boost
if 'timestamp' in result.get('metadata', {}):
age_days = (datetime.now() - datetime.fromisoformat(
result['metadata']['timestamp']
)).days
recency_factor = max(0.8, 1 - (age_days / 365))
score *= recency_factor
return min(score, 1.0)
Source Attribution
def _extract_source_info(self, result: Dict[str, Any]) -> Dict[str, Any]:
"""Extract and validate source information."""
try:
source_info = {
'file_path': None,
'type': None,
'line_number': None,
'commit_hash': None,
'last_modified': None,
'contributor': None
}
metadata = result.get('metadata', {})
# Extract basic info
source_info['file_path'] = metadata.get('file_path')
source_info['type'] = metadata.get('type')
# Extract detailed info if available
if 'details' in metadata:
details = metadata['details']
source_info['line_number'] = details.get('line_number')
source_info['commit_hash'] = details.get('commit_hash')
source_info['last_modified'] = details.get('last_modified')
source_info['contributor'] = details.get('contributor')
# Validate source info
if not source_info['file_path']:
self.logger.warning("Missing source file path")
return None
return source_info
except Exception as e:
self.logger.error(f"Error extracting source info: {e}")
return None
Quality Assurance
class ContextRetriever:
def _verify_context_quality(self, context: Dict[str, Any]) -> bool:
"""Verify context quality with comprehensive checks."""
try:
if not context:
return False
# Check for minimum content
total_items = sum(
len(items) for items in context.values()
if isinstance(items, list)
)
if total_items == 0:
return False
# Verify content relevance
relevant_items = 0
required_score = 0.3
for items in context.values():
if not isinstance(items, list):
continue
for item in items:
if item.get('relevance_score', 0) >= required_score:
relevant_items += 1
if relevant_items == 0:
return False
# Verify source attribution
if not self._verify_sources(context):
return False
# Verify content diversity
if not self._verify_content_diversity(context):
return False
return True
except Exception as e:
self.logger.error(f"Error verifying context quality: {e}")
return False
def _verify_sources(self, context: Dict[str, Any]) -> bool:
"""Verify source attribution quality."""
for items in context.values():
if not isinstance(items, list):
continue
for item in items:
if not item.get('source_info'):
self.logger.warning("Missing source information")
return False
if not item['source_info'].get('file_path'):
self.logger.warning("Missing source file path")
return False
return True
def _verify_content_diversity(self, context: Dict[str, Any]) -> bool:
"""Verify content type diversity."""
content_types = set()
for items in context.values():
if not isinstance(items, list):
continue
for item in items:
content_type = item.get('metadata', {}).get('type')
if content_type:
content_types.add(content_type)
# Require at least 2 different content types
return len(content_types) >= 2
Context Retrieval Flow

Configuration Options
# context_retrieval_config.yaml
retrieval:
min_similarity_score: 0.2
max_results: 10
enable_fallback: true
search:
term_expansion: true
include_metadata: true
parallel_search: true
ranking:
enable_comprehensive_scoring: true
recency_weight: 0.2
type_match_boost: 1.2
entity_match_boost: 1.1
quality:
required_score: 0.3
min_content_types: 2
verify_sources: true
performance:
cache_results: true
cache_ttl: 3600
batch_size: 5
The Context Retrieval system provides:
- Sophisticated content identification
- Advanced ranking and filtering
- Comprehensive source attribution
- Robust quality assurance
- Performance optimization
- Configurable behavior
5.3 Response Generation
LLM Integration with GPT-4
# src/ai_processing/llm_interface.py
class LLMInterface:
"""Interface for advanced LLM interaction with GPT-4."""
def __init__(self, api_key: str):
self.logger = logging.getLogger(__name__)
self.client = AsyncOpenAI(api_key=api_key)
# Load prompt templates
self.base_prompts = {
'api': self._load_prompt_template('api'),
'code': self._load_prompt_template('code'),
'documentation': self._load_prompt_template('documentation'),
'setup': self._load_prompt_template('setup')
}
@retry(stop=stop_after_attempt(3), wait=wait_exponential(multiplier=1, min=4, max=10))
async def generate_response(
self,
query: str,
context: Dict[str, Any],
processed_query: Dict[str, Any]
) -> Dict[str, Any]:
"""Generate response with enhanced context verification."""
try:
# Verify context sufficiency
if not self._verify_context_sufficiency(context):
return self._create_insufficient_context_response(query)
# Construct prompts
system_prompt = self._construct_system_prompt(
processed_query['query_type']
)
user_prompt = self._construct_user_prompt(
query,
context,
processed_query
)
# Enhanced RAG enforcement
rag_enforcement = self._create_rag_enforcement()
# Generate response with GPT-4
response = await self.client.chat.completions.create(
model="gpt-4-0125-preview",
messages=[
{"role": "system", "content": system_prompt},
rag_enforcement,
{"role": "user", "content": user_prompt}
],
temperature=0.7,
max_tokens=2000
)
# Process and verify response
processed_response = self._process_response(response, context)
# Verify context usage
if not self._verify_response_uses_context(
processed_response,
context
):
processed_response = self._add_context_warning(
processed_response
)
return processed_response
except Exception as e:
self.logger.error(f"Error generating response: {e}")
raise
Response Formatting and Generation
# src/ai_processing/response_generator.py
class ResponseGenerator:
"""Generate and format responses with quality control."""
def __init__(self):
self.logger = logging.getLogger(__name__)
def generate_response(
self,
llm_response: Dict[str, Any],
processed_query: Dict[str, Any],
context: Dict[str, Any]
) -> Dict[str, Any]:
"""Generate final response with formatting and citations."""
try:
# Format the response content
formatted_content = self._format_response_content(
llm_response['answer']
)
# Extract and verify citations
citations = self._extract_citations(
formatted_content,
context
)
# Add code snippets if relevant
code_snippets = self._extract_code_snippets(
formatted_content
) if 'code' in processed_query['query_type'] else []
# Generate response with sections
response = {
'answer': formatted_content,
'citations': citations,
'code_snippets': code_snippets,
'metadata': {
'query_type': processed_query['query_type'],
'context_used': self._summarize_context(context),
'generation_timestamp': datetime.now().isoformat()
}
}
# Verify response quality
if not self._verify_response_quality(response):
return self._create_fallback_response(
processed_query,
context
)
return response
except Exception as e:
self.logger.error(f"Error generating response: {e}")
raise
def _format_response_content(self, content: str) -> str:
"""Format response content with enhanced markdown."""
# Clean up markdown formatting
content = re.sub(r'\n{3,}', '\n\n', content)
# Format code blocks
content = re.sub(
r'```(?!python|bash|json|yaml)',
'```python',
content
)
# Format inline code
content = re.sub(r'`([^`]+)`', r'`\1`', content)
# Add section headers
sections = content.split('\n\n')
formatted_sections = []
for i, section in enumerate(sections):
if i == 0 or not section.startswith('#'):
formatted_sections.append(section)
else:
formatted_sections.append(f"\n{section}")
return '\n\n'.join(formatted_sections)
Source Citation Management
def _extract_citations(
self,
content: str,
context: Dict[str, Any]
) -> List[Dict[str, Any]]:
"""Extract and verify source citations."""
citations = []
seen_sources = set()
# Extract explicit citations
explicit_citations = re.finditer(
r'(?:Source|From|In):\s+([^\n]+)',
content
)
for match in explicit_citations:
source = match.group(1).strip()
if source not in seen_sources:
citation = self._verify_citation(source, context)
if citation:
citations.append(citation)
seen_sources.add(source)
# Add implicit citations based on content matching
for content_type, items in context.items():
if not isinstance(items, list):
continue
for item in items:
source = item.get('metadata', {}).get('file_path')
if source and source not in seen_sources:
content_snippet = str(item.get('content', ''))
if self._content_matches_response(content_snippet, content):
citations.append({
'source': source,
'type': content_type,
'relevance': item.get('relevance_score', 0.0)
})
seen_sources.add(source)
return citations
def _verify_citation(
self,
source: str,
context: Dict[str, Any]
) -> Optional[Dict[str, Any]]:
"""Verify citation against context."""
for content_type, items in context.items():
if not isinstance(items, list):
continue
for item in items:
if item.get('metadata', {}).get('file_path') == source:
return {
'source': source,
'type': content_type,
'relevance': item.get('relevance_score', 0.0)
}
return None
Quality Control
def _verify_response_quality(self, response: Dict[str, Any]) -> bool:
"""Comprehensive response quality verification."""
try:
# Check response length
if len(response['answer']) < 50:
self.logger.warning("Response too short")
return False
# Verify citations
if not self._verify_citations_quality(response['citations']):
return False
# Check code snippets if present
if response['code_snippets']:
if not self._verify_code_snippets(response['code_snippets']):
return False
# Verify content relevance
if not self._verify_content_relevance(
response['answer'],
response['metadata']['query_type']
):
return False
# Check for hallucinations
if self._detect_hallucinations(response):
return False
return True
except Exception as e:
self.logger.error(f"Error verifying response quality: {e}")
return False
def _verify_citations_quality(self, citations: List[Dict[str, Any]]) -> bool:
"""Verify quality of citations."""
if not citations:
self.logger.warning("No citations found")
return False
# Check citation relevance
relevant_citations = [
c for c in citations
if c.get('relevance', 0) > 0.3
]
if len(relevant_citations) < 1:
self.logger.warning("No relevant citations")
return False
return True
def _detect_hallucinations(self, response: Dict[str, Any]) -> bool:
"""Detect potential hallucinations in response."""
# Check for unsupported claims
content = response['answer'].lower()
suspicious_phrases = [
'always',
'never',
'all',
'every',
'guaranteed',
'perfect'
]
for phrase in suspicious_phrases:
if phrase in content:
# Verify phrase against context
if not self._verify_absolute_claim(
phrase,
content,
response['citations']
):
return True
# Check numerical claims
numbers = re.findall(r'\d+(?:\.\d+)?', content)
for number in numbers:
if not self._verify_numerical_claim(
number,
content,
response['citations']
):
return True
return False
Response Generation Flow

Configuration Options
# response_generation_config.yaml
llm:
model: "gpt-4-0125-preview"
temperature: 0.7
max_tokens: 2000
formatting:
enable_markdown: true
code_block_languages:
- python
- bash
- json
- yaml
citations:
require_citations: true
min_citations: 1
verify_sources: true
quality:
min_response_length: 50
min_citation_relevance: 0.3
check_hallucinations: true
fallback:
enable_fallback: true
max_retries: 2
verification:
check_absolute_claims: true
verify_numbers: true
suspicious_phrases:
- always
- never
- all
- every
- guaranteed
- perfect
The Response Generation system provides:
- Robust LLM integration
- Sophisticated response formatting
- Comprehensive citation management
- Strong quality control measures
- Hallucination detection
- Fallback mechanisms
6. Implementation Details
6.1 Key Technologies
Python Ecosystem Components
# requirements.txt
# Core Dependencies
streamlit>=1.24.0,<2.0.0
chromadb>=0.5.17
openai>=1.0.0
GitPython==3.1.31
langchain==0.0.300
python-dotenv==1.0.0
beautifulsoup4==4.12.2
pytest==7.3.1
tenacity>=8.2.3
grpcio==1.67.1
chroma-hnswlib==0.7.6
# Data Processing
numpy>=1.24.0
pandas>=2.0.0
scipy>=1.10.0
# Async Support
aiohttp>=3.8.0
asyncio>=3.4.3
httpx>=0.24.0
# Development Tools
black>=23.0.0
isort>=5.12.0
pylint>=2.17.0
mypy>=1.3.0
ChromaDB Integration
# src/storage/vector_store.py
class VectorStore:
def __init__(self, persist_directory: str):
self.client = chromadb.PersistentClient(path=persist_directory)
# Configure embedding function
self.embedding_function = embedding_functions.OpenAIEmbeddingFunction(
api_key=os.getenv('OPENAI_API_KEY'),
model_name="text-embedding-3-small",
dimensions=1536
)
# Initialize collections with optimized settings
self.collections = self._initialize_collections()
def _initialize_collections(self) -> Dict[str, Any]:
"""Initialize ChromaDB collections with optimized settings."""
collections = {}
# Code collection
collections['code'] = self.client.get_or_create_collection(
name="code_snippets",
embedding_function=self.embedding_function,
metadata={"description": "Code snippets from the repository"},
# Optimized distance metrics for code
distance_metric="cosine"
)
# Documentation collection
collections['documentation'] = self.client.get_or_create_collection(
name="documentation",
embedding_function=self.embedding_function,
metadata={"description": "Documentation content"},
distance_metric="cosine"
)
return collections
def _optimize_chromadb(self):
"""Apply ChromaDB optimization settings."""
# Configure ChromaDB settings
self.client.heartbeat() # Ensure connection
# Set persistent directory settings
os.makedirs(self.persist_directory, exist_ok=True)
# Configure HNSW index parameters
index_params = {
"M": 64, # Number of connections per element
"efConstruction": 200, # Size of dynamic candidate list
"ef": 100 # Size of dynamic candidate list for search
}
return index_params
OpenAI Integration
# src/ai_processing/llm_interface.py
class LLMInterface:
def __init__(self, api_key: str):
self.client = AsyncOpenAI(api_key=api_key)
self.model_config = {
'model': "gpt-4-0125-preview",
'temperature': 0.7,
'max_tokens': 2000,
'top_p': 1,
'frequency_penalty': 0,
'presence_penalty': 0
}
async def generate_response(
self,
query: str,
context: Dict[str, Any],
processed_query: Dict[str, Any]
) -> Dict[str, Any]:
"""Generate response using GPT-4 with optimized settings."""
try:
# Prepare messages with context
messages = self._prepare_messages(query, context, processed_query)
# Configure request timeout and retries
timeout_config = httpx.Timeout(
connect=5.0,
read=30.0,
write=10.0,
pool=2.0
)
# Make API call with optimized settings
response = await self.client.chat.completions.create(
messages=messages,
**self.model_config,
request_timeout=timeout_config
)
return self._process_response(response, context)
except Exception as e:
self.logger.error(f"Error in GPT-4 generation: {e}")
raise
def _prepare_messages(
self,
query: str,
context: Dict[str, Any],
processed_query: Dict[str, Any]
) -> List[Dict[str, str]]:
"""Prepare optimized messages for GPT-4."""
messages = [
{
"role": "system",
"content": self._construct_system_prompt(
processed_query['query_type']
)
},
{
"role": "system",
"content": self._create_rag_enforcement()
},
{
"role": "user",
"content": self._construct_user_prompt(
query,
context,
processed_query
)
}
]
return messages
Streamlit UI Implementation
# src/ui/app.py
class WhisperAssistantUI:
def __init__(self):
self.logger = logging.getLogger(__name__)
self._verify_data_exists()
self._initialize_session_state()
self._setup_components()
def render(self):
"""Render the main UI with optimized components."""
st.set_page_config(
page_title="Whisper Repository Assistant",
page_icon="🤖",
layout="wide",
initial_sidebar_state="auto"
)
# Apply custom styling
self._apply_custom_styles()
# Create responsive layout
col1, col2 = st.columns([2, 1])
with col1:
self._render_chat_interface()
with col2:
self._render_code_viewer()
def _render_chat_interface(self):
"""Render optimized chat interface."""
# Custom chat container
chat_container = st.container()
with chat_container:
# Display chat history
for message in st.session_state.chat_history:
self.chat_interface.display_message(
message['role'],
message['content']
)
# Query input with auto-focus
query = st.text_input(
"Ask about the Whisper repository:",
key="query_input",
on_change=self._handle_input_change
)
# Submit button with keyboard shortcut
if st.button(
"Submit",
key="submit_button",
help="Press Enter to submit"
) or self._check_enter_pressed():
self._handle_query(query)
SQLite Metadata Store
# src/storage/metadata_store.py
class MetadataStore:
def __init__(self, db_path: str, preserve_data: bool = True):
self.db_path = db_path
self._initialize_db()
def _initialize_db(self):
"""Initialize SQLite with optimized configuration."""
try:
with sqlite3.connect(self.db_path) as conn:
# Enable WAL mode for better concurrent access
conn.execute('PRAGMA journal_mode=WAL')
# Optimize performance
conn.execute('PRAGMA synchronous=NORMAL')
conn.execute('PRAGMA temp_store=MEMORY')
conn.execute('PRAGMA mmap_size=30000000000')
conn.execute('PRAGMA cache_size=-2000') # 2MB cache
# Create optimized tables
self._create_tables(conn)
# Create indexes
self._create_indexes(conn)
conn.commit()
except Exception as e:
self.logger.error(f"Database initialization error: {e}")
raise
def _create_indexes(self, conn: sqlite3.Connection):
"""Create optimized indexes for common queries."""
cursor = conn.cursor()
# Create indexes with careful consideration
indexes = [
'CREATE INDEX IF NOT EXISTS idx_api_name ON api_metadata(name)',
'CREATE INDEX IF NOT EXISTS idx_api_file ON api_metadata(file_path)',
'CREATE INDEX IF NOT EXISTS idx_env_name ON env_variables(name)',
'CREATE INDEX IF NOT EXISTS idx_file_path ON file_metadata(file_path)',
'CREATE INDEX IF NOT EXISTS idx_repo_key ON repository_info(key)'
]
for index in indexes:
cursor.execute(index)
Technology Integration Diagram
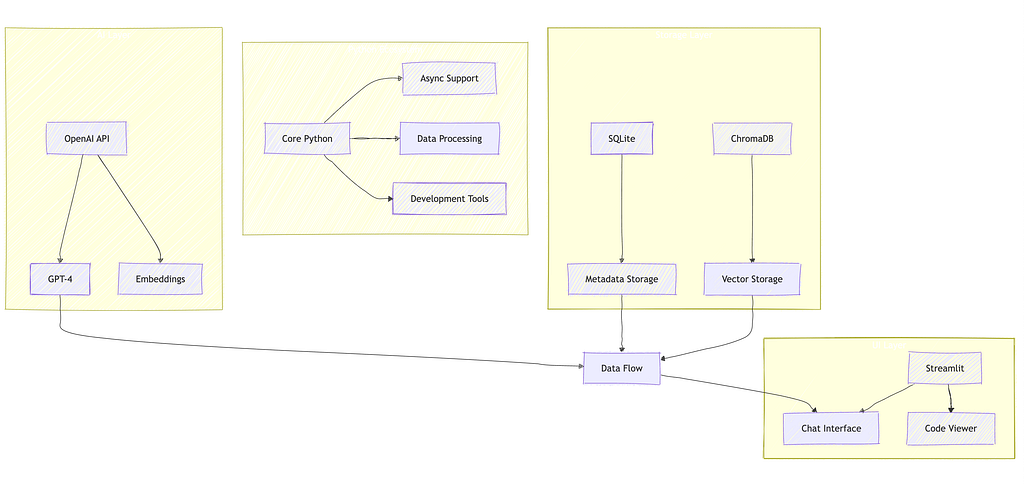
Performance Optimization Examples:
# Example performance optimizations for each technology
# ChromaDB Optimization
def optimize_chromadb_settings(collection):
"""Optimize ChromaDB collection settings."""
return {
"hnsw_config": {
"M": 64,
"efConstruction": 200,
"ef": 100
},
"mmap_config": {
"enabled": True,
"size_limit": "2GB"
}
}
# SQLite Optimization
def optimize_sqlite_connection(conn):
"""Optimize SQLite connection settings."""
optimizations = [
'PRAGMA journal_mode=WAL',
'PRAGMA synchronous=NORMAL',
'PRAGMA temp_store=MEMORY',
'PRAGMA mmap_size=30000000000',
'PRAGMA cache_size=-2000',
'PRAGMA page_size=4096'
]
for opt in optimizations:
conn.execute(opt)
# OpenAI API Optimization
def optimize_openai_requests(batch_size: int = 5):
"""Optimize OpenAI API request batching."""
return {
'max_retries': 3,
'timeout': 30,
'batch_size': batch_size,
'rate_limit_pause': 0.1
}
# Streamlit Performance
def optimize_streamlit_performance():
"""Optimize Streamlit UI performance."""
st.set_page_config(
layout="wide",
initial_sidebar_state="collapsed"
)
# Cache expensive computations
@st.cache_data(ttl=3600)
def get_cached_data():
return expensive_computation()
Configuration Management
# config/technology_stack.yaml
python_ecosystem:
min_version: "3.8"
async_support: true
data_processing:
numpy: true
pandas: true
chromadb:
persist_directory: "./data/embeddings"
optimization:
hnsw_config:
M: 64
efConstruction: 200
ef: 100
mmap_enabled: true
openai:
model: "gpt-4-0125-preview"
embedding_model: "text-embedding-3-small"
optimization:
batch_size: 5
max_retries: 3
timeout: 30
streamlit:
layout: "wide"
theme:
primaryColor: "#FF4B4B"
backgroundColor: "#FFFFFF"
optimization:
cache_ttl: 3600
sqlite:
journal_mode: "WAL"
synchronous: "NORMAL"
cache_size: 2000
page_size: 4096
Each technology is carefully integrated with:
- Optimized configurations
- Performance tuning
- Error handling
- Monitoring capabilities
- Scaling considerations
6.2 Code Organization
Project Structure Overview
whisper-assistant/
├── src/
│ ├── ai_processing/
│ │ ├── __init__.py
│ │ ├── query_processor.py
│ │ ├── context_retriever.py
│ │ ├── llm_interface.py
│ │ └── response_generator.py
│ ├── data_ingestion/
│ │ ├── __init__.py
│ │ ├── repo_crawler.py
│ │ ├── code_parser.py
│ │ └── extractors/
│ │ ├── api_extractor.py
│ │ ├── doc_extractor.py
│ │ └── env_extractor.py
│ ├── storage/
│ │ ├── __init__.py
│ │ ├── vector_store.py
│ │ ├── metadata_store.py
│ │ └── cache.py
│ └── ui/
│ ├── __init__.py
│ ├── app.py
│ ├── components/
│ │ ├── chat.py
│ │ └── code_viewer.py
│ └── utils/
│ └── formatting.py
├── config/
│ ├── default.yaml
│ ├── development.yaml
│ └── production.yaml
├── tests/
│ ├── unit/
│ ├── integration/
│ └── e2e/
└── scripts/
├── setup.py
└── deploy.sh
Module Responsibilities
# src/ai_processing/__init__.py
"""
Module: AI Processing
Responsibility: Orchestrates the AI-powered query processing and response generation
Components:
- Query Processing: Analyzes and classifies user queries
- Context Retrieval: Fetches relevant context from storage
- LLM Integration: Handles GPT-4 interaction
- Response Generation: Formats and validates responses
"""
# src/data_ingestion/__init__.py
"""
Module: Data Ingestion
Responsibility: Handles repository data extraction and processing
Components:
- Repository Crawler: Clones and navigates repositories
- Code Parser: Analyzes Python code structure
- Extractors: Specialized components for different content types
"""
# src/storage/__init__.py
"""
Module: Storage
Responsibility: Manages data persistence and retrieval
Components:
- Vector Store: Handles embeddings and semantic search
- Metadata Store: Manages structured data
- Cache: Optimizes response times
"""
# src/ui/__init__.py
"""
Module: UI
Responsibility: Provides user interface and interaction
Components:
- Chat Interface: Handles user conversations
- Code Viewer: Displays code snippets and documentation
- Formatting Utils: Manages content presentation
"""
Interface Definitions
# src/core/interfaces.py
from abc import ABC, abstractmethod
from typing import Dict, List, Any, Optional
class StorageInterface(ABC):
"""Abstract interface for storage implementations."""
@abstractmethod
async def store(self, key: str, data: Any) -> bool:
"""Store data with given key."""
pass
@abstractmethod
async def retrieve(self, key: str) -> Optional[Any]:
"""Retrieve data for given key."""
pass
@abstractmethod
async def search(self, query: str) -> List[Dict[str, Any]]:
"""Search stored data."""
pass
class ProcessorInterface(ABC):
"""Abstract interface for content processors."""
@abstractmethod
async def process(self, content: Any) -> Dict[str, Any]:
"""Process content and return structured data."""
pass
@abstractmethod
async def validate(self, processed_data: Dict[str, Any]) -> bool:
"""Validate processed data."""
pass
class LLMInterface(ABC):
"""Abstract interface for LLM interactions."""
@abstractmethod
async def generate_response(
self,
query: str,
context: Dict[str, Any]
) -> Dict[str, Any]:
"""Generate response using LLM."""
pass
@abstractmethod
async def validate_response(
self,
response: Dict[str, Any],
context: Dict[str, Any]
) -> bool:
"""Validate LLM response."""
pass
Configuration Management
# src/core/config.py
from pathlib import Path
from typing import Dict, Any
import yaml
import os
class ConfigManager:
"""Manages application configuration with environment awareness."""
def __init__(self):
self.env = os.getenv('APP_ENV', 'development')
self.config_dir = Path('config')
self.config: Dict[str, Any] = {}
self._load_config()
def _load_config(self):
"""Load configuration files with inheritance."""
try:
# Load default config
default_config = self._load_yaml('default.yaml')
# Load environment-specific config
env_config = self._load_yaml(f'{self.env}.yaml')
# Merge configurations
self.config = self._deep_merge(default_config, env_config)
# Override with environment variables
self._override_from_env()
except Exception as e:
raise ConfigurationError(f"Error loading config: {e}")
def _load_yaml(self, filename: str) -> Dict[str, Any]:
"""Load and parse YAML configuration file."""
file_path = self.config_dir / filename
if not file_path.exists():
return {}
with open(file_path, 'r') as f:
return yaml.safe_load(f)
def _deep_merge(self, base: Dict, override: Dict) -> Dict:
"""Deep merge two dictionaries."""
result = base.copy()
for key, value in override.items():
if isinstance(value, dict):
result[key] = self._deep_merge(
base.get(key, {}),
value
)
else:
result[key] = value
return result
def _override_from_env(self):
"""Override configuration with environment variables."""
prefix = 'APP_'
for key, value in os.environ.items():
if key.startswith(prefix):
config_key = key[len(prefix):].lower()
self._set_nested_value(self.config, config_key, value)
def _set_nested_value(
self,
config: Dict,
key: str,
value: str
):
"""Set nested configuration value."""
keys = key.split('_')
current = config
for k in keys[:-1]:
current = current.setdefault(k, {})
current[keys[-1]] = value
def get(self, key: str, default: Any = None) -> Any:
"""Get configuration value with dot notation."""
try:
value = self.config
for k in key.split('.'):
value = value[k]
return value
except (KeyError, TypeError):
return default
Example Configuration Files:
# config/default.yaml
app:
name: "Whisper Repository Assistant"
version: "1.0.0"
storage:
vector_store:
engine: "chromadb"
persist_directory: "./data/embeddings"
metadata_store:
engine: "sqlite"
db_path: "./data/metadata.db"
cache:
enabled: true
ttl: 3600
ai_processing:
model: "gpt-4-0125-preview"
temperature: 0.7
max_tokens: 2000
data_ingestion:
batch_size: 5
file_types:
- ".py"
- ".md"
- ".txt"
logging:
level: "INFO"
format: "%(asctime)s - %(name)s - %(levelname)s - %(message)s"
# config/development.yaml
storage:
vector_store:
persist_directory: "./data/dev/embeddings"
metadata_store:
db_path: "./data/dev/metadata.db"
logging:
level: "DEBUG"
ai_processing:
temperature: 0.8
# config/production.yaml
storage:
vector_store:
persist_directory: "/data/prod/embeddings"
metadata_store:
db_path: "/data/prod/metadata.db"
logging:
level: "WARNING"
cache:
ttl: 7200
Module Import Organization
# Example of organized imports
from src.ai_processing import (
QueryProcessor,
ContextRetriever,
LLMInterface,
ResponseGenerator
)
from src.data_ingestion import (
RepoCrawler,
CodeParser,
APIExtractor,
DocExtractor,
EnvExtractor
)
from src.storage import (
VectorStore,
MetadataStore,
Cache
)
from src.ui import (
ChatInterface,
CodeViewer,
FormattingUtils
)
Project Entry Points
# run.py
from src.core.config import ConfigManager
from src.ui.app import WhisperAssistantUI
import logging
def setup_logging(config: ConfigManager):
"""Setup logging configuration."""
logging.basicConfig(
level=config.get('logging.level', 'INFO'),
format=config.get(
'logging.format',
'%(asctime)s - %(name)s - %(levelname)s - %(message)s'
)
)
def main():
"""Application entry point."""
# Initialize configuration
config = ConfigManager()
# Setup logging
setup_logging(config)
# Initialize and run UI
app = WhisperAssistantUI()
app.render()
if __name__ == "__main__":
main()
The code organization provides:
- Clear module separation
- Well-defined interfaces
- Flexible configuration management
- Environment-specific settings
- Organized import structure
- Centralized entry points
7. Advanced Features
7.1 RAG Implementation
Context Verification System
# src/ai_processing/rag/context_verifier.py
class ContextVerifier:
"""Advanced context verification for RAG implementation."""
def __init__(self):
self.logger = logging.getLogger(__name__)
self.min_similarity_threshold = 0.2
self.min_context_length = 100
self.required_context_types = {'code', 'documentation'}
async def verify_context(
self,
context: Dict[str, Any],
query: str
) -> Tuple[bool, Dict[str, Any]]:
"""Verify context quality and relevance."""
try:
verification_results = {
'sufficient_content': False,
'content_relevance': 0.0,
'context_diversity': 0.0,
'source_reliability': 0.0
}
# Check content sufficiency
if not self._verify_content_sufficiency(context):
return False, verification_results
verification_results['sufficient_content'] = True
# Check content relevance
relevance_score = await self._verify_content_relevance(
context,
query
)
if relevance_score < self.min_similarity_threshold:
return False, verification_results
verification_results['content_relevance'] = relevance_score
# Check context diversity
diversity_score = self._calculate_context_diversity(context)
verification_results['context_diversity'] = diversity_score
# Verify source reliability
reliability_score = self._verify_source_reliability(context)
verification_results['source_reliability'] = reliability_score
# Calculate final verification result
is_verified = all([
verification_results['sufficient_content'],
verification_results['content_relevance'] >= self.min_similarity_threshold,
verification_results['context_diversity'] >= 0.3,
verification_results['source_reliability'] >= 0.7
])
return is_verified, verification_results
except Exception as e:
self.logger.error(f"Context verification error: {e}")
return False, verification_results
def _verify_content_sufficiency(self, context: Dict[str, Any]) -> bool:
"""Verify if context contains sufficient content."""
# Check for minimum content length
total_content = sum(
len(str(item.get('content', '')))
for items in context.values()
if isinstance(items, list)
for item in items
)
if total_content < self.min_context_length:
return False
# Verify required context types
present_types = set(context.keys())
if not self.required_context_types.issubset(present_types):
return False
return True
async def _verify_content_relevance(
self,
context: Dict[str, Any],
query: str
) -> float:
"""Verify content relevance using semantic similarity."""
relevance_scores = []
for context_type, items in context.items():
if not isinstance(items, list):
continue
for item in items:
if not isinstance(item, dict):
continue
content = str(item.get('content', ''))
score = await self._calculate_semantic_similarity(
query,
content
)
relevance_scores.append(score)
return max(relevance_scores) if relevance_scores else 0.0
Response Validation System
# src/ai_processing/rag/response_validator.py
class ResponseValidator:
"""Advanced response validation for RAG responses."""
def __init__(self):
self.logger = logging.getLogger(__name__)
async def validate_response(
self,
response: Dict[str, Any],
context: Dict[str, Any],
query: str
) -> Tuple[bool, Dict[str, Any]]:
"""Validate response against context and query."""
validation_results = {
'factual_accuracy': 0.0,
'context_adherence': 0.0,
'source_attribution': 0.0,
'response_completeness': 0.0,
'issues': []
}
try:
# Check factual accuracy
factual_score = await self._verify_factual_accuracy(
response['answer'],
context
)
validation_results['factual_accuracy'] = factual_score
# Verify context adherence
adherence_score = self._verify_context_adherence(
response['answer'],
context
)
validation_results['context_adherence'] = adherence_score
# Check source attribution
attribution_score = self._verify_source_attribution(
response['answer'],
response.get('citations', [])
)
validation_results['source_attribution'] = attribution_score
# Verify response completeness
completeness_score = self._verify_completeness(
response['answer'],
query
)
validation_results['response_completeness'] = completeness_score
# Detect potential issues
issues = self._detect_issues(response['answer'], context)
validation_results['issues'] = issues
# Calculate overall validation result
is_valid = (
factual_score >= 0.8 and
adherence_score >= 0.7 and
attribution_score >= 0.9 and
completeness_score >= 0.7 and
not any(issue['severity'] == 'high' for issue in issues)
)
return is_valid, validation_results
except Exception as e:
self.logger.error(f"Response validation error: {e}")
return False, validation_results
async def _verify_factual_accuracy(
self,
response: str,
context: Dict[str, Any]
) -> float:
"""Verify factual accuracy against context."""
facts = self._extract_factual_claims(response)
verified_facts = 0
for fact in facts:
if await self._verify_fact_in_context(fact, context):
verified_facts += 1
return verified_facts / len(facts) if facts else 0.0
Source Attribution System
# src/ai_processing/rag/source_attributor.py
class SourceAttributor:
"""Advanced source attribution for RAG responses."""
def __init__(self):
self.logger = logging.getLogger(__name__)
def process_sources(
self,
response: str,
context: Dict[str, Any]
) -> Dict[str, Any]:
"""Process and validate source attributions."""
try:
# Extract explicit citations
explicit_citations = self._extract_explicit_citations(response)
# Find implicit references
implicit_references = self._find_implicit_references(
response,
context
)
# Verify all sources
verified_sources = self._verify_sources(
explicit_citations,
implicit_references,
context
)
# Generate source metadata
source_metadata = self._generate_source_metadata(
verified_sources,
context
)
return {
'explicit_citations': explicit_citations,
'implicit_references': implicit_references,
'verified_sources': verified_sources,
'metadata': source_metadata
}
except Exception as e:
self.logger.error(f"Source attribution error: {e}")
return {}
def _verify_sources(
self,
explicit_citations: List[Dict[str, Any]],
implicit_references: List[Dict[str, Any]],
context: Dict[str, Any]
) -> List[Dict[str, Any]]:
"""Verify all sources against context."""
verified_sources = []
for citation in explicit_citations + implicit_references:
if source := self._verify_source_in_context(
citation,
context
):
verified_sources.append({
**citation,
'verification': source
})
return verified_sources
Accuracy Improvement System
# src/ai_processing/rag/accuracy_improver.py
class AccuracyImprover:
"""Advanced accuracy improvements for RAG system."""
def __init__(self):
self.logger = logging.getLogger(__name__)
async def improve_accuracy(
self,
response: Dict[str, Any],
context: Dict[str, Any],
query: str
) -> Dict[str, Any]:
"""Improve response accuracy through multiple techniques."""
try:
# Initial response analysis
analysis = await self._analyze_response(response, context)
# Apply improvements based on analysis
improved_response = response.copy()
if analysis['needs_fact_verification']:
improved_response = await self._verify_facts(
improved_response,
context
)
if analysis['needs_source_enhancement']:
improved_response = await self._enhance_sources(
improved_response,
context
)
if analysis['needs_clarification']:
improved_response = await self._add_clarifications(
improved_response,
context
)
# Final quality check
quality_metrics = self._calculate_quality_metrics(
improved_response,
context
)
return {
'response': improved_response,
'improvements': analysis,
'quality_metrics': quality_metrics
}
except Exception as e:
self.logger.error(f"Accuracy improvement error: {e}")
return response
async def _verify_facts(
self,
response: Dict[str, Any],
context: Dict[str, Any]
) -> Dict[str, Any]:
"""Verify and correct factual statements."""
facts = self._extract_facts(response['answer'])
verified_response = response.copy()
corrections = []
for fact in facts:
verification = await self._verify_fact(fact, context)
if not verification['is_verified']:
correction = await self._generate_correction(
fact,
verification,
context
)
corrections.append(correction)
if corrections:
verified_response['answer'] = self._apply_corrections(
verified_response['answer'],
corrections
)
verified_response['corrections'] = corrections
return verified_response
RAG Process Flow
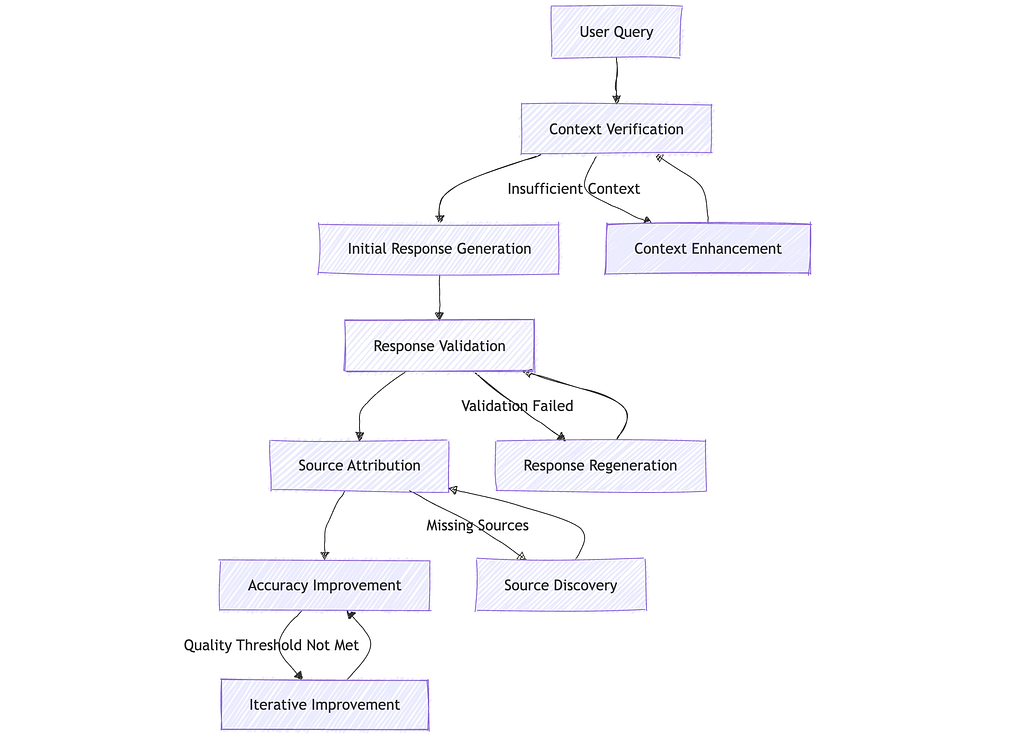
Configuration Options
# rag_config.yaml
context_verification:
min_similarity_threshold: 0.2
min_context_length: 100
required_context_types:
- code
- documentation
response_validation:
factual_accuracy_threshold: 0.8
context_adherence_threshold: 0.7
source_attribution_threshold: 0.9
completeness_threshold: 0.7
source_attribution:
verify_explicit_citations: true
find_implicit_references: true
require_source_metadata: true
accuracy_improvement:
enable_fact_verification: true
enable_source_enhancement: true
enable_clarifications: true
max_improvement_iterations: 3
quality_metrics:
min_quality_score: 0.8
required_metrics:
- factual_accuracy
- context_adherence
- source_attribution
- response_completeness
7.2 Cache Management
Core Cache Implementation
# src/storage/cache.py
from typing import Optional, Dict, Any, List
import time
import json
from datetime import datetime
from collections import OrderedDict
import logging
from threading import Lock
class CacheManager:
"""Advanced cache management system with optimization strategies."""
def __init__(
self,
max_size: int = 1000,
ttl: int = 3600,
cleanup_interval: int = 300
):
self.logger = logging.getLogger(__name__)
self.max_size = max_size
self.ttl = ttl
self.cleanup_interval = cleanup_interval
# Primary cache storage
self.cache: OrderedDict = OrderedDict()
# Secondary caches for different types of data
self.response_cache: Dict = {}
self.embedding_cache: Dict = {}
self.metadata_cache: Dict = {}
# Cache statistics
self.stats = CacheStats()
# Thread safety
self.lock = Lock()
# Last cleanup timestamp
self.last_cleanup = time.time()
async def get(self, key: str) -> Optional[Any]:
"""Get item from cache with advanced retrieval strategy."""
try:
with self.lock:
self._maybe_cleanup()
if key not in self.cache:
self.stats.record_miss()
return None
entry = self.cache[key]
current_time = time.time()
# Check if entry is expired
if current_time - entry['timestamp'] > self.ttl:
del self.cache[key]
self.stats.record_expiration()
return None
# Update access patterns
entry['access_count'] += 1
entry['last_accessed'] = current_time
# Move to end (most recently used)
self.cache.move_to_end(key)
self.stats.record_hit()
return entry['data']
except Exception as e:
self.logger.error(f"Cache retrieval error: {e}")
return None
async def set(
self,
key: str,
value: Any,
ttl: Optional[int] = None
) -> bool:
"""Set item in cache with advanced storage strategy."""
try:
with self.lock:
self._maybe_cleanup()
# Check cache size limit
if len(self.cache) >= self.max_size:
self._evict_entries()
# Create cache entry
entry = {
'data': value,
'timestamp': time.time(),
'ttl': ttl or self.ttl,
'access_count': 0,
'last_accessed': time.time(),
'size': self._calculate_size(value)
}
self.cache[key] = entry
self.stats.record_set()
return True
except Exception as e:
self.logger.error(f"Cache storage error: {e}")
return False
Cache Invalidation Strategies
class CacheManager:
def _evict_entries(self):
"""Implement multiple eviction strategies."""
try:
with self.lock:
# Start with expired entries
self._remove_expired()
# If still over limit, use combined strategy
while len(self.cache) >= self.max_size:
# Score entries based on multiple factors
entries_scores = []
current_time = time.time()
for key, entry in self.cache.items():
score = self._calculate_eviction_score(
entry,
current_time
)
entries_scores.append((key, score))
# Sort by score (lower is better to keep)
entries_scores.sort(key=lambda x: x[1], reverse=True)
# Remove highest scored entry
if entries_scores:
key_to_remove = entries_scores[0][0]
del self.cache[key_to_remove]
self.stats.record_eviction()
except Exception as e:
self.logger.error(f"Cache eviction error: {e}")
def _calculate_eviction_score(
self,
entry: Dict[str, Any],
current_time: float
) -> float:
"""Calculate entry score for eviction."""
# Factors to consider:
# 1. Time since last access (higher is worse)
time_factor = (current_time - entry['last_accessed']) / self.ttl
# 2. Access frequency (lower is worse)
frequency_factor = 1.0 / (entry['access_count'] + 1)
# 3. Size factor (higher is worse)
size_factor = entry['size'] / self._get_average_entry_size()
# 4. TTL proximity (closer to expiration is worse)
ttl_factor = (current_time - entry['timestamp']) / entry['ttl']
# Combine factors with weights
score = (
time_factor * 0.4 +
frequency_factor * 0.3 +
size_factor * 0.2 +
ttl_factor * 0.1
)
return score
Performance Optimization
class CacheManager:
def _optimize_memory_usage(self):
"""Optimize cache memory usage."""
try:
current_memory = self._estimate_memory_usage()
target_memory = self._get_target_memory_usage()
if current_memory > target_memory:
reduction_needed = current_memory - target_memory
# Strategy 1: Remove least accessed entries
self._remove_least_accessed(reduction_needed * 0.4)
# Strategy 2: Compress large entries
self._compress_large_entries()
# Strategy 3: Reduce TTL for old entries
self._adjust_ttl_for_old_entries()
self.stats.record_optimization()
except Exception as e:
self.logger.error(f"Memory optimization error: {e}")
async def get_optimized(
self,
key: str,
loader: callable
) -> Optional[Any]:
"""Get with optimized loading strategy."""
try:
# Try cache first
if cached := await self.get(key):
return cached
# Load and cache if not found
value = await loader()
if value is not None:
await self.set(key, value)
return value
except Exception as e:
self.logger.error(f"Optimized retrieval error: {e}")
return None
Memory Management
class MemoryManager:
"""Manage memory usage for cache system."""
def __init__(self, cache_manager: CacheManager):
self.cache_manager = cache_manager
self.logger = logging.getLogger(__name__)
self.memory_threshold = 0.8 # 80% of available memory
async def monitor_memory(self):
"""Monitor and manage memory usage."""
try:
while True:
current_usage = self._get_memory_usage()
if current_usage > self.memory_threshold:
await self._reduce_memory_usage()
await asyncio.sleep(60) # Check every minute
except Exception as e:
self.logger.error(f"Memory monitoring error: {e}")
async def _reduce_memory_usage(self):
"""Implement memory reduction strategies."""
try:
# Strategy 1: Clear expired entries
self.cache_manager._remove_expired()
# Strategy 2: Compress large entries
self._compress_large_entries()
# Strategy 3: Evict least valuable entries
if self._get_memory_usage() > self.memory_threshold:
self._evict_by_value()
except Exception as e:
self.logger.error(f"Memory reduction error: {e}")
def _compress_large_entries(self):
"""Compress entries exceeding size threshold."""
try:
for key, entry in self.cache_manager.cache.items():
if entry['size'] > self._get_compression_threshold():
compressed_data = self._compress_data(entry['data'])
entry['data'] = compressed_data
entry['size'] = self._calculate_size(compressed_data)
entry['is_compressed'] = True
except Exception as e:
self.logger.error(f"Compression error: {e}")
Cache Statistics and Monitoring
class CacheStats:
"""Track and analyze cache performance metrics."""
def __init__(self):
self.stats = {
'hits': 0,
'misses': 0,
'sets': 0,
'evictions': 0,
'expirations': 0,
'optimizations': 0
}
self.start_time = time.time()
self.access_patterns: Dict[str, int] = {}
def get_metrics(self) -> Dict[str, Any]:
"""Get comprehensive cache metrics."""
total_requests = self.stats['hits'] + self.stats['misses']
uptime = time.time() - self.start_time
return {
'hit_rate': self.stats['hits'] / total_requests if total_requests > 0 else 0,
'miss_rate': self.stats['misses'] / total_requests if total_requests > 0 else 0,
'eviction_rate': self.stats['evictions'] / self.stats['sets'] if self.stats['sets'] > 0 else 0,
'optimization_rate': self.stats['optimizations'] / uptime * 3600, # per hour
'average_key_lifetime': self._calculate_average_lifetime(),
'memory_efficiency': self._calculate_memory_efficiency()
}
def record_hit(self): self.stats['hits'] += 1
def record_miss(self): self.stats['misses'] += 1
def record_set(self): self.stats['sets'] += 1
def record_eviction(self): self.stats['evictions'] += 1
def record_expiration(self): self.stats['expirations'] += 1
def record_optimization(self): self.stats['optimizations'] += 1
Cache Management Flow
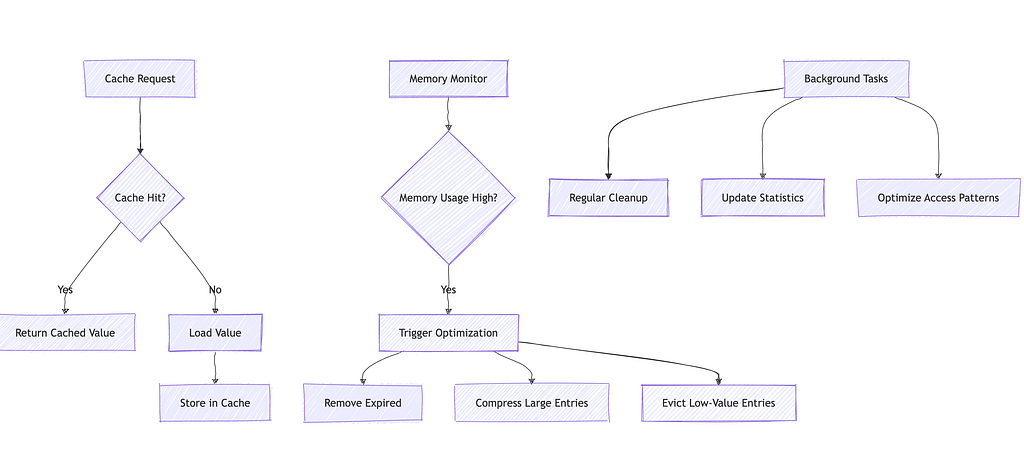
Configuration Options
# cache_config.yaml
cache:
max_size: 1000
ttl: 3600
cleanup_interval: 300
memory:
threshold: 0.8
compression_threshold: 1048576 # 1MB
check_interval: 60
optimization:
enable_compression: true
enable_auto_cleanup: true
enable_memory_monitoring: true
eviction:
strategy: combined # Options: lru, lfu, size, combined
weights:
time_factor: 0.4
frequency_factor: 0.3
size_factor: 0.2
ttl_factor: 0.1
statistics:
enable_monitoring: true
metrics_interval: 300
log_level: INFO
The Cache Management system provides:
- Efficient caching strategies
- Smart cache invalidation
- Performance optimization
- Memory management
- Comprehensive monitoring
- Configuration flexibility
9. Future Improvements
Planned Enhancements
1. Advanced RAG Capabilities
# Planned implementation for enhanced RAG
class AdvancedRAGProcessor:
"""Next-generation RAG implementation with advanced features."""
def __init__(self):
self.chunk_strategies = {
'semantic': SemanticChunker(),
'hybrid': HybridChunker(),
'adaptive': AdaptiveChunker()
}
self.reranker = ContextReranker()
async def process_query(
self,
query: str,
context: Dict[str, Any]
) -> Dict[str, Any]:
"""Enhanced query processing with advanced context handling."""
try:
# Implement multi-stage retrieval
initial_results = await self._initial_retrieval(query)
reranked_results = self.reranker.rerank(
query,
initial_results
)
# Dynamic context fusion
fused_context = self._fuse_context(
reranked_results,
query
)
# Structured reasoning
reasoning_chain = await self._structured_reasoning(
query,
fused_context
)
return {
'response': reasoning_chain.generate_response(),
'context': fused_context,
'reasoning': reasoning_chain.get_steps()
}
except Exception as e:
self.logger.error(f"Advanced RAG processing error: {e}")
raise
2. Enhanced Code Analysis
# Future code analysis improvements
class EnhancedCodeAnalyzer:
"""Advanced code analysis with semantic understanding."""
def __init__(self):
self.semantic_parser = SemanticCodeParser()
self.dependency_analyzer = DependencyAnalyzer()
self.flow_analyzer = CodeFlowAnalyzer()
async def analyze_codebase(
self,
repo_path: str
) -> Dict[str, Any]:
"""Comprehensive codebase analysis."""
try:
# Semantic understanding
semantic_model = await self.semantic_parser.parse_repo(
repo_path
)
# Advanced dependency tracking
dependency_graph = self.dependency_analyzer.build_graph(
semantic_model
)
# Control flow analysis
flow_patterns = self.flow_analyzer.analyze_patterns(
semantic_model
)
# Generate comprehensive insights
insights = self._generate_insights(
semantic_model,
dependency_graph,
flow_patterns
)
return {
'semantic_model': semantic_model,
'dependencies': dependency_graph,
'flow_analysis': flow_patterns,
'insights': insights
}
except Exception as e:
self.logger.error(f"Enhanced code analysis error: {e}")
raise
3. Performance Optimizations
# Future performance enhancements
class PerformanceOptimizer:
"""System-wide performance optimization."""
def __init__(self):
self.query_optimizer = QueryOptimizer()
self.cache_optimizer = CacheOptimizer()
self.resource_manager = ResourceManager()
async def optimize_system(
self,
performance_metrics: Dict[str, Any]
) -> Dict[str, Any]:
"""Implement system-wide optimizations."""
optimizations = {
'query_processing': await self._optimize_queries(),
'caching': await self._optimize_caching(),
'resource_usage': await self._optimize_resources()
}
return optimizations
async def _optimize_queries(self) -> Dict[str, Any]:
"""Optimize query processing pipeline."""
return {
'vectorization': {
'batch_size': self.query_optimizer.get_optimal_batch_size(),
'parallel_processing': True,
'caching_strategy': 'adaptive'
},
'context_retrieval': {
'index_type': 'hybrid',
'search_algorithm': 'approximate_nearest_neighbors',
'optimization_level': 'aggressive'
}
}
Please check out this repo for all the code:
GitHub – esenthil2018/whisper_assistant: Repository Assistant
Current Limitations and Future Scope
This project serves as a proof-of-concept template demonstrating how to build an AI-powered repository assistant. While currently focused on Python, Markdown, and text files from the Whisper repository, there’s significant room for expansion and improvement.
Current Limitations
- Docker implementation is pending
- Test suite needs to be completed
- Limited to specific file types (Python, Markdown, text)
- Focused on single repository analysis
Future Possibilities
This template can be expanded to:
- Support additional programming languages (JavaScript, Java, C++, etc.)
- Handle multiple repository types
- Include more advanced code analysis features
- Implement comprehensive testing
- Add containerization support
Using This Template
We encourage developers to use this codebase as a starting point to:
- Build more comprehensive repository assistants
- Add support for their preferred programming languages
- Implement additional features and capabilities
- Enhance the analysis capabilities
Think of this project as a foundation — it shows the basic architecture and implementation patterns for building an AI-powered repository assistant. While it successfully demonstrates the concept with Python files, it’s designed to be extended and enhanced for broader applications.
Whether you’re interested in adding support for new languages, implementing advanced features, or adapting it for different use cases, this template provides the essential building blocks to get started.
Remember: This is not a final product but rather a demonstration of possibilities in the field of AI-assisted code understanding and documentation.
10. Conclusion
Lessons Learned
Technical Insights
class ProjectInsights:
"""Key lessons from project implementation."""
@staticmethod
def get_technical_lessons() -> Dict[str, List[str]]:
return {
"rag_implementation": [
"Context quality is crucial for response accuracy",
"Source attribution needs rigorous verification",
"Response validation should be multi-layered",
"Cache management significantly impacts performance"
],
"architecture": [
"Modular design enables easier updates",
"Clear interfaces improve maintainability",
"Configuration management needs centralization",
"Error handling requires comprehensive approach"
],
"performance": [
"Early optimization can be counterproductive",
"Monitoring is essential for optimization",
"Caching strategies need regular review",
"Resource usage requires constant monitoring"
]
}
@staticmethod
def get_process_lessons() -> Dict[str, List[str]]:
return {
"development": [
"Incremental development is more manageable",
"Testing should be comprehensive from start",
"Documentation needs continuous updating",
"Code review improves overall quality"
],
"deployment": [
"Configuration management is critical",
"Monitoring setup should be early",
"Backup strategies need testing",
"Rollback plans are essential"
]
}
Best Practices
Code Organization
# Example of implemented best practices
class BestPractices:
"""Collection of implemented best practices."""
@staticmethod
def code_organization() -> Dict[str, str]:
return {
"modularity": """
Break code into logical, focused modules
Use clear interface definitions
Implement separation of concerns
Maintain single responsibility principle
""",
"configuration": """
Centralize configuration management
Use environment-specific configs
Implement validation for configs
Maintain secure credential handling
""",
"error_handling": """
Implement comprehensive error handling
Use appropriate error hierarchies
Maintain detailed error logging
Implement graceful degradation
""",
"testing": """
Write comprehensive unit tests
Implement integration testing
Maintain continuous testing
Use test-driven development
"""
}
@staticmethod
def performance_practices() -> Dict[str, str]:
return {
"caching": """
Implement intelligent caching
Use appropriate invalidation
Monitor cache performance
Optimize cache strategies
""",
"optimization": """
Profile before optimizing
Focus on bottlenecks
Measure improvement impact
Document optimization decisions
"""
}
Development Guidelines
# development_guidelines.yaml
code_quality:
- Use type hints consistently
- Write comprehensive docstrings
- Follow PEP 8 style guide
- Maintain code documentation
testing:
- Write unit tests for new features
- Maintain integration tests
- Perform performance testing
- Document test cases
deployment:
- Use continuous integration
- Implement automated testing
- Maintain deployment scripts
- Document deployment process
monitoring:
- Implement comprehensive logging
- Set up performance monitoring
- Track error rates
- Monitor resource usage
Demystifying Code Repositories: Building an AI Assistant for Code Understanding was originally published in Level Up Coding on Medium, where people are continuing the conversation by highlighting and responding to this story.
This content originally appeared on Level Up Coding – Medium and was authored by Senthil E