This content originally appeared on DEV Community and was authored by Benedetto Proietti
Or obsession for control?
Let’s admit it: we love the idea of running SQL queries on ALL our data! Not just a preference — it feels like an obsession. No matter how old or how rarely accessed, we cling to the idea that everything must remain instantly queryable.
It feels so simple, until it’s not. And then bad things happen:
The database grows too large, and queries slow down to death.
Indexes sizes explode, eating up CPU and memory just to keep up.
Schema changes become a nightmare, locking tables and causing downtime.
The cost of scaling up SQL infrastructure skyrockets.
Suddenly, our beautiful, structured world starts crumbling under its own weight. What seemed like an easy decision — “let’s just store everything in SQL” — becomes a scaling bottleneck that forces us to rethink our approach.
But why does this happen?
Relational Databases are powerful because they provide structure, indexing, and queryability — elements that make it easy for users to analyze and manipulate data.
For engineers, analysts, and business users, SQL offers:
A universal way to query data — The language is standardized and widely understood.
Ad-hoc queryability — You can ask complex questions without predefining reports.
Data consistency — Enforced schemas and constraints prevent data corruption.
Indexing for performance — The ability to speed up searches through optimized indexes.
Because of these benefits, many organizations enforce SQL as the default, even when other approaches may be more suitable.
But what happens when this need for structure becomes a liability rather than an asset?
We will look a bit into the problem space, and then we will explore (not exhaustively!) the solution space.
2. The Problem space: When Structure Becomes a Limitation
2.1. The cost of our need for Structure
While SQL provides clarity, it also introduces constraints. Let’s look at the most important ones.
Schema
A schema demands data to be organized in a set of tables. And for each table it needs a set of columns (names and types) and primary key column. You can also introduce relationships between tables, but we are not going to talk about that here (that’s why, incidentally, they are called “relational databases”).
Schema changes are delicate operations. They must be deployed before application changes to ensure compatibility. But even when done correctly, they introduce risks — what if your production data has unexpected edge cases your test environment didn’t? What if rollback becomes a nightmare?
Oh wait! Do we push the DB schema changes first, or the application changes first? schema changes first of course! Then just pray that the application you are pushing has the exact same schema. Yes you tested in the test environment… which is always perfectly identical to the production environment… right?
Well… not always.
Indices
A dear friend of mine and accomplished engineer used to say that “writing Databases is the art of writing indices”.
What is an index? An index is a type of data structure that helps finding the data when you do a search.
You put the data into a table as it comes. Now you want to search for all the orders for Mr Smith. If you indexed the LastName column…. The index has an acceleration data structure (probably a kind of tree) where it quickly can find all the rows where the last name is equal to “Smith”.
Nice right? Yah.
You know what it takes? Let’s try to list of what it takes:
· Fast memory (RAM) where to keep the fast data structure.
· Time: it needs to lock the index while it is searching it, so that mutations on the index do not make it crash. Yes these locks can be avoided or reduced most of the times but… you get the gist. Let’s stop it here for now.
Now what happens if you need more data?
You need more memory? Sure but there’s a limit to physical memory on a single machine.
Let’s go distributed, let’s use a cluster. Now I ask you to do the mental exercise to imagine how to lock a distributed index data structure across a cluster of 4 nodes. Well… difficult but possible.
But what if your data is really, REALLY huge? You might need 400 nodes. Or 4,000. Or 40,000. It’s impossible. Why?
Because indexes improve query speed — but they also introduce contention. Updating an index requires locking portions of it, slowing down concurrent writes. In a single-node setup, this is manageable. But in a distributed database spanning hundreds of nodes, keeping indexes in sync becomes a nightmare. This is why most distributed databases avoid global indexes or use eventually consistent indexing approaches. Without careful design, a single overloaded index update can throttle an entire system, creating cascading slowdowns.
And probably spending so much time and engineering effort in calibrating indexes does not align with your core business.
Conclusions so far
That’s why you need to give up and think about other ways of storing your data.
The first place you store the data “in general” should not go into a relational SQL database (RDBMs if we want to use a formal language). That might not be the case for specific cases, for example where credit cards or money is involved.
If you are convinced about that, please continue reading. Otherwise please stop reading. There is no value for you to continue.
3. Exploring the solution space
3.1. Hot/Cold
First of all, not all data needs to be hot. Or indexed.
In most of the use cases queries need last week’s data, or last month’s data. Why then are you keeping 3 years’ worth of data in expensive indexed RDBMs?
1 week out of 3 years is less than one percent of the entire data! (0.6% to be precise).
1 month out of 3 years is about 2.5% of the entire data.
Maybe, it makes sense to place “hot” data in a fast (and costly) database (or even a cache), and the cold data in a cheaper (and slower) data storage. It will cost a bit in terms of latency to access such data but… you will save a ton on money.
So why do companies still keep years of data in expensive RDBMS instances? Often, it’s habit — ‘we might need it someday’ — or a lack of proper data lifecycle planning. But in reality, only a fraction of the data needs to remain hot.
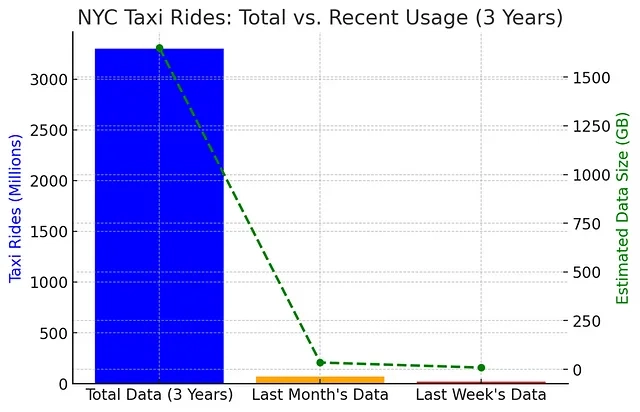
A real-world Example
A real-world example of this concept is NYC Taxi ride data:
· Total Dataset: ~1.1 billion rides per year (~550GB of storage).
· Last 3 years of data: ~3.3 billion rides (~1.6 TB of storage).
· Last Month’s Data: ~70 million rides (~35GB of storage).
· Last Week’s Data: ~18 million rides (~9GB of storage).
3.2. Columns
I have often seen relational databases with hundreds — sometimes even thousands — of columns, storing an incredible amount of data. Yet, most of these columns are rarely queried. They can’t be discarded because they hold valuable information, but they still come at a cost.
Every column, whether used frequently or not, adds overhead in disk storage, CPU, and memory — even when it’s not indexed. And that brings us to another issue: we can’t index all hundreds of columns for obvious reasons. As a result, we end up in a paradoxical situation:
We pay for an expensive and often slow relational database system.
Yet, hundreds of columns remain unindexed, making queries inefficient.
This raises an important question: Are we truly benefiting from keeping all columns “hot” and queryable, or are we just paying for an illusion of accessibility?
4. Big Data: an introduction
The term Big Data is thrown around a lot, but how big is “big”?
Here’s my personal definition: Big Data is an amount of data that cannot fit in a small cluster — but it still needs to be queryable.
A modern approach to Big Data consists of several components, and the key principle is separating compute from storage.
4.1. Storage: The Data Lake
Big Data is typically stored in a distributed object storage system, which I loosely call a Data Lake.
Here’s my informal definition of a Data Lake:
Virtually infinite capacity — There is no practical storage limit.
Massively parallel — It can handle many simultaneous operations.
High throughput — Huge input/output bandwidth.
High latency — It is not optimized for low-latency access.
Simple REST API — Accessible through standard cloud APIs.
4.2. Compute: Processing Data from the Data Lake
From the Data Lake, data branches into separate workflows:
Analytics workloads → Data warehouses, batch processing, OLAP queries.
Online applications → Real-time transactional workloads (OLTP), NoSQL solutions.
But before going further, let me clarify something crucial:
4.3. Analytics & Online Processing Should Be Completely Separate
They should not share the same datastore, cluster, or even availability zone.
Why?
Analytics deals with historical data — end-of-day sales reports, customer behavior insights, trend analysis, etc.
Online processing serves live production workloads — API responses, real-time transactions, and user interactions.
Mixing the two is a huge risk. Allowing analytical queries to run on your live production system is an enterprise disaster waiting to happen. You risk:
 Slow application performance — Customers may experience delays.
Slow application performance — Customers may experience delays.
Production downtime — A heavy analytical query could lock tables or exhaust resources.
Jeopardizing business operations — A reporting query should never interfere with live transactions.
 DO NOT DO IT. Keep them separate.
DO NOT DO IT. Keep them separate.
Besides, each requires different technologies:
Online processing → Needs an RDBMS (SQL or NoSQL). These systems are designed for transactional speed and reliability.
Analytics → Requires Big Data tools to efficiently process vast datasets.
4.4. Analytics Compute: Processing Big Data
There are many ways to query and process Big Data. A full discussion would take an entire book, so here’s a short list of key technologies:
Spark
 The de facto distributed compute engine for Big Data.
The de facto distributed compute engine for Big Data.
Has been around since 2014, gaining widespread adoption.
Processes petabytes of data with relative ease.
 Not without its issues, but still one of the easiest ways to run large-scale distributed queries.
Not without its issues, but still one of the easiest ways to run large-scale distributed queries.
Flink
A newer competitor to Spark, with fresher architecture.
Focuses on real-time and batch processing.
Similar trade-offs as Spark but gaining traction.
AWS Athena
Serverless querying of S3 data.
Pay-as-you-go pricing (great for occasional queries).
Can become expensive at scale if queries are frequent.
ClickHouse
The cool new kid in town — Incredibly fast analytics.
Can store data internally or query data directly from S3.
Supports indexes, making queries much faster than traditional Data Lakes.
Available as fully managed or self-hosted.
 An excellent choice for high-performance analytics.
An excellent choice for high-performance analytics.
AWS Redshift (or another DataWarehouse)
This is a crossover scenario. Redshift is a semi-managed RDBMS but with beefy architecture, a columnar approach (why is columnar better? That’s a question for another article) a lot of cache and a cluster architecture that makes it super-fast.
Redshift offers fast, scalable columnar storage, making it great for heavy analytical queries. But it comes at a cost — both financial and operational. While Redshift excels for structured reporting, it’s not ideal for ad-hoc exploratory analysis, where a more flexible solution like Athena or ClickHouse might be better.
4.5. Final Thoughts on BigData
Big Data requires rethinking storage and compute:
· Store everything in a Data Lake (cheap, scalable storage).
· Compute happens separately, using the right tool for the job.
· Never mix analytics with production systems — that’s asking for trouble.
Big Data isn’t about blindly throwing everything into SQL — it’s about choosing the right technologies for scale, cost, and performance.
The diagram (source: AWS documentation) depicts a serverless “datalake centric” analytics architecture
5. Small Data: Flexibility & Fewer Constraints
When dealing with small datasets, storage flexibility is far greater than in the Big Data world.
Unlike Big Data, where storage and compute must be carefully architected, small data is forgiving.
You don’t have to worry about distributed storage, multi-cluster orchestration, or separating compute from storage.
Instead, you get to focus on what really matters: choosing the right tool for the job.
5.1. Where Can You Store Small Data?
With small datasets, you have many options:
· SQL databases — Classic, structured, reliable. Perfect for transactional workloads.
· NoSQL databases — Flexible, schema-free, and great for hierarchical or document-based data.
· Flat files (CSV, JSON, Parquet) — Easy to use, easy to share. Works great for logs, configs, and lightweight processing.
· In-memory databases (Redis, Memcached) — Blazing fast, ideal for caching and ephemeral data storage.
· Embedded databases (SQLite, DuckDB) — Self-contained, no external dependencies, excellent for local processing.
Each of these options has trade-offs, but the beauty of small data is that you don’t need a complex architecture.
You pick what works and move forward — no need for extensive capacity planning or complex scaling strategies.
5.2. The Cost vs. Performance Trade-Off
With small data, performance and cost concerns are less critical compared to Big Data.
· Scaling is rarely an issue — One machine, or a few, are usually enough.
· Disk and memory overhead is minimal — A few gigabytes of data can fit comfortably on SSDs or even in memory.
· Cold vs. hot data isn’t a problem — All data is small enough to be ‘hot’ by default.
But there’s still an important question to ask:
5.3. Structure vs Flexibility
With small datasets, the temptation is to throw everything into SQL, because it just works. But does it always make sense?
· If your data is deeply hierarchical (e.g., JSON, XML), would a document store be a better fit?
· If your access patterns are key-value based, why not use an in-memory store like Redis?
· If your data is static, would a simple CSV or JSON file suffice instead of a full-blown database?
SQL forces structure, which is great when you need consistency, transactions, and relational integrity.
But flexibility is often more important when dealing with small, isolated datasets that don’t require complex relationships.
5.4. Over-engineering
I’ve seen teams deploy Kafka clusters to process just a few thousand messages per day — a classic case of overengineering. Sometimes, a simple cron job writing to an SQLite database does the job just fine.
5.5. Final Thoughts
With Big Data, you need careful storage and compute separation just to make the system work.
With small data, you don’t. You have options, and you should take advantage of them.
· Don’t default to SQL just because it’s familiar.
· Think about your access patterns first.
· Pick the simplest tool that solves the problem.
After all, flexibility is the true advantage of small data. 
5.6. Big or Small Data
Many workloads labeled as ‘Big Data’ are simply poorly optimized small data.
The industry loves the term, but not all “Big Data problems” are truly big. Sometimes, what appears to be a scaling issue is just a lack of proper indexing, partitioning, or query optimization.
- If your system struggles to process a few terabytes of structured data, you might not need Hadoop or Spark — you may just need better schema design and indexing.
- If your pipeline relies on daily batch jobs to process logs, a simpler event-driven system with proper aggregation could be more efficient than a full-blown Big Data stack. Before reaching for complex distributed computing tools, ask: Do I have a Big Data problem, or do I have a poorly optimized Small Data problem?
5.7. Conclusion
SQL databases are a great tool — but not the only tool. The human desire for structure often leads us to over-rely on relational databases, even when they introduce inefficiencies.
The best architecture balances structure with flexibility. Before defaulting to SQL, ask yourself:
Does all this data need to be hot and indexed?
Is SQL the right tool, or am I forcing structure where it’s not needed?
Can I reduce costs and improve performance with a better data lifecycle strategy?
Are you dealing with SQL scalability headaches?
If your data is growing and you’re unsure how to scale without breaking the bank, let’s talk. I help teams with architecture and modernization strategies — reach out if you need a second opinion.
PS: Feel free to also visit my informal podcast “PROIEX — Tech Experiences”.
This content originally appeared on DEV Community and was authored by Benedetto Proietti