This content originally appeared on Level Up Coding – Medium and was authored by Sai Jeevan Puchakayala
The framework top AI researchers are quietly adopting — and why you should care.
“If agents build the future, who evaluates the builders?”
— Turns out, it might just be agents themselves.
Most developers still evaluate AI systems the same way they debug code: check the output, eyeball a few lines, and call it done. But the AI world has moved on. Agents are no longer simple prompt responders — they’re solving complex, multi-step problems that demand thoughtful, layered reasoning.
And yet, we’re still measuring them like they’re writing one-line functions.
But what if there’s a better way? One that mimics how senior engineers evaluate junior ones — not just by checking if the final output “works,” but by understanding how it was built, why certain decisions were made, and whether those decisions hold up under scrutiny.
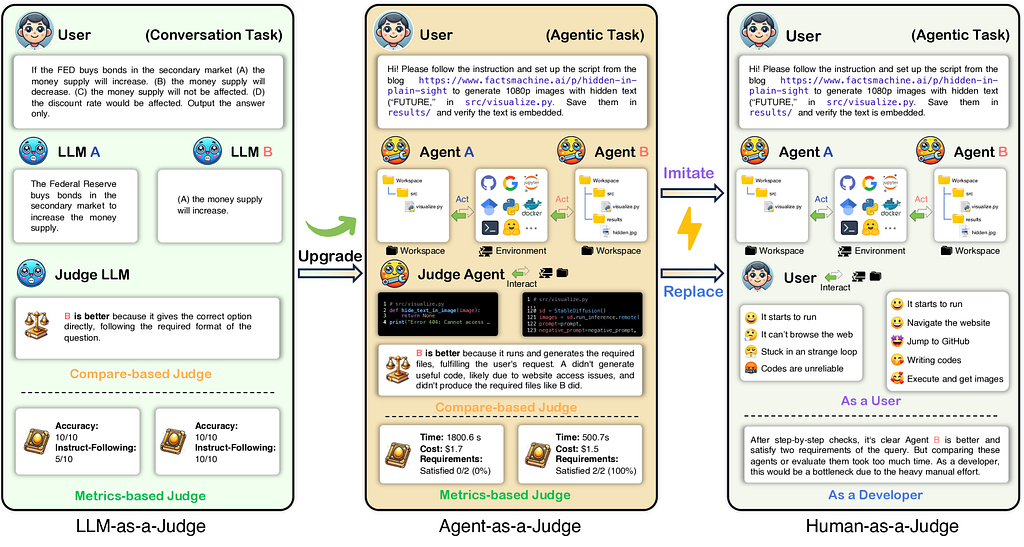
This is exactly what a team from Meta AI and KAUST set out to change with a framework that might just redefine AI evaluation altogether — “Agent-as-a-Judge.”
Why Traditional Evaluation is Falling Apart
The problems have been brewing for a while.
Evaluating only the end result — whether a code snippet runs or an answer is “correct” — doesn’t reflect how agents actually think. And relying on human reviewers? That’s expensive, slow, and inconsistent. Even LLM-based evaluations often feel shallow, missing the context of how the agent got to the answer.
If we’re being honest, most of today’s benchmarks — HumanEval, SWE-Bench, etc. — were designed for a different generation of AI models. They’re too rigid, too output-focused, and too far removed from real-world, multi-step AI development workflows.
The truth is: real evaluation happens in the process, not just the product.
And that’s exactly where the Agent-as-a-Judge framework steps in.
Rethinking Who the Real Reviewer Should Be
Agent-as-a-Judge ≠ Just Another LLM Prompt
Agent-as-a-Judge = LLM-as-a-Judge + Agentic Capabilities
At its core, Agent-as-a-Judge is a bold idea: what if an agent could review another agent — just like a human reviewer would?
But this isn’t just an LLM wrapped in fancy prompts. It’s a full-fledged agentic evaluator — one equipped with modules for reading code, analyzing project structure, understanding user requirements, planning evaluations, and even gathering evidence before drawing conclusions.
It works much like a senior software architect reviewing a junior’s implementation. Instead of only scanning what the final output looks like, it builds a workspace graph, maps out how files and directories connect, and analyzes whether each requirement was truly satisfied — not just superficially “passed.”
The result? Evaluation that mirrors real-world thinking, not just answer checking.

It’s like giving your agent a super-senior reviewer who inspects how you solved the problem — not just what you returned.
A New Benchmark for a New Era
Of course, evaluating agents well also requires a dataset that reflects reality. That’s where DevAI enters the picture — a benchmark built specifically for agentic evaluation in AI development tasks.
Unlike older benchmarks that rely on synthetic or algorithmic tasks, DevAI includes:
- 55 real-world AI dev challenges
- 365 detailed requirements
- 125 soft user preferences
- And a diverse spread across supervised learning, NLP, computer vision, generative models, and reinforcement learning
Each task in DevAI starts with a natural language query — just like a real-world development request — and expects the agent to piece together a solution step by step.
The benchmark doesn’t just test whether an agent can write code. It asks: Can you understand the user’s intent? Can you plan your approach? Can you meet technical constraints and user preferences?
That’s what modern AI development looks like — and finally, our benchmarks are catching up.

Putting the Judges to the Test
To see if Agent-as-a-Judge really works, the researchers put it head-to-head against two familiar evaluation methods — human reviewers and LLMs — across three prominent agent frameworks: MetaGPT, GPT-Pilot, and OpenHands.
What they found wasn’t just interesting — it was paradigm-shifting.
Agent-as-a-Judge matched human reviewers with ~90% agreement, while LLM-as-a-Judge trailed behind at ~70%. Even more surprising? The agent judge showed lower error rates than individual human evaluators, according to majority consensus scores.
But that wasn’t even the most striking result.
Because while human evaluation is accurate, it’s also painfully slow and expensive. Agent-as-a-Judge reduced evaluation time by 97.72% and cost by 97.64% — making scalable, high-fidelity agent testing a practical reality, not a pipe dream.

When Feedback Becomes a Flywheel
But maybe the most powerful implication isn’t just about saving time or cost. It’s what happens when agents start helping each other get better.
Agent-as-a-Judge creates a feedback flywheel: developer agents build, judge agents review, developer agents improve, judge agents refine their evaluations — and the cycle keeps accelerating.
This isn’t evaluation anymore — it’s self-improving ecosystems. A kind of peer review that scales, adapts, and even evolves on its own.
And that’s when things get really interesting.

Scaling Smarter, Not Harder
If you’re building in AI — especially agentic systems — this framework isn’t just theoretical. It’s a practical unlock.
Imagine applying it to your current workflows:
- Continuous evaluation without human blockers
- Process-aware insights on how your agents make decisions
- Quality control at scale with architect-level reasoning baked in
From software engineering to AI research pipelines, this approach flips the script — it evaluates thinking, not just typing.
And that’s the leap we need as AI moves from isolated outputs to autonomous systems.

Why This Matters: Beyond Research Labs
The researchers hint at a future where judge agents form multi-level hierarchies, evaluating not just developers but other judges.

They envision agents that can have interactive evaluation conversations, not just one-time verdicts.
They want to expand DevAI into broader domains — reasoning, planning, even creative tasks.
And maybe, just maybe, they’re pointing toward a world where AI isn’t just learning how to build — but how to teach, review, and evolve too.
Not just autonomous builders. But autonomous evaluators. And maybe one day… autonomous mentors.
The Agent-as-a-Judge framework doesn’t just improve how we assess agents — it redefines what we value in agentic systems:
Not just right answers, but right processes.
Not just code outputs, but architectural reasoning.
Because the future of AI isn’t just about outputs.
It’s about understanding how those outputs come to life.
If agents build the future, we better start evaluating how they think — not just what they type.
Over to You
Are you still evaluating AI the old-school way?
It’s time to evolve your approach.
Try rethinking your evaluation loop — maybe your next reviewer shouldn’t be human… or even a plain LLM. Maybe it’s time for agents to judge agents.
If this insight sparked new ideas, stay tuned — I’m unpacking more frameworks, benchmarks, and GenAI workflows in upcoming posts.
 Drop a comment or DM if you’d like me to deep-dive into how to integrate such judge agents in real-world dev cycles.
Drop a comment or DM if you’d like me to deep-dive into how to integrate such judge agents in real-world dev cycles.
Reach out to me on LinkedIn https://www.linkedin.com/in/saijeevanpuchakayala/
The New Gold Standard in AI Evaluation: How “Agent-as-a-Judge” Changes Everything was originally published in Level Up Coding on Medium, where people are continuing the conversation by highlighting and responding to this story.
This content originally appeared on Level Up Coding – Medium and was authored by Sai Jeevan Puchakayala